




ALE
Reasons for Distributing Business Functions
In a modern company, the flows of logistics and information between the various organizational units are likely to be sizable and complex. One reason for this is the adoption of new management concepts like "lean production".
Many previously centralized responsibilities are now being assigned to the organizational units that are directly linked to the relevant information or to the production.
The assignment of business management functions like inventory management, central purchasing or financial accounting to the various organizational units is not the same in every company.
There is a tendency in some areas towards an increasing independence between business units within a company. This lends itself to the idea of modeling intra-company relationships along the same lines as customer-vendor relationships.
Market requirements have led to many changes in business processes. These have increased the demands on process flows in areas such as purchasing, sales and distribution, production and accounting.
The increasing integration of business processes means that they can no longer be modeled in terms of a single company only. Relationships with customers and vendors must also be considered.
Distributing these various tasks away from the center means that a high level of communication is demanded from integration functions. Fast access to information held in other areas is required (for example, the sales department may require information on the stocks of finished products in the individual plants).
Distributed Responsibilities in a Company.
Users of modern business data processing systems require:
a high degree of integration between business application systems to ensure effective modeling of business processes
decoupled application systems that can be implemented decentrally and independently of any particular technology.
The design, construction and operation of complex, enterprise-wide, distributed application systems remains one of the greatest challenges in data processing. The conventional solutions available today do not provide a totally satisfactory answer to the diverse needs of today's users.
Further standardization of business processes accompanied by ever tighter integration within a central system no longer represents a practicable approach to the problem.
The following are some of the most commonly encountered difficulties:
• technical bottlenecks,
• upgrade problems,
• the effect of time zones on international corporations,
• excessively long response times in large centralized systems.
For these reasons a number of R/2 customers operate several systems in parallel (arranged, for example, on a geographical basis). Whilst the three-tier client-server architecture of the R/3 System means that the significance of these technical restrictions is somewhat reduced, they are still present.
Whilst the idea of using distributed databases to implement distributed application systems sounds tempting, this is rarely a practical approach these days. The reasons for this include high communications overhead, uneconomic data processing operations and inadequate security mechanisms.
ALE - The Objectives
ALE (Application Link Enabling) supports the construction and operation of distributed applications. ALE handles the exchange of business data messages across loosely coupled SAP applications, ensuring that data is consistent. Applications are integrated by using synchronous and asynchronous communication, rather than by means of a central database.
ALE comprises three layers:
1. applications
2. distribution
3. communication
In order to meet the requirements of today's customers and to be open for future developments, ALE must meet the following challenges:
Communication between different software releases
Continued data exchange after a release upgrade without special maintenance.
Independence of the technical format of a message from its contents
Extensions that can be made easily, even by customers
Applications that are decoupled from the communication
Communications interfaces that allow connections to third-party applications
Support for R/3-R/2 scenarios
ALE - The Concept
The basic principle behind ALE is the guarantee of a distributed, yet fully integrated, R/3 System installation. Each application is self-sufficient and exists in the distributed environment with its own set of data.
Distributed databases are rarely a good solution today to the problem of data transport for the following reasons:
The R/3 System contains consistency checks that could not be performed in an individual database. Replicating tables in distributed databases would render these consistency checks useless.
Mirrored tables require two-phase commits. These result in a heavy loss of performance.
The distribution is controlled at the level of tables for distributed databases, and at the level of the applications in the case of ALE distribution.
Long distance access to distributed data can be difficult even today (because of error rates, a high level of network activity and long response times).
The use of self-sufficient systems implies a certain measure of data redundancy. Therefore data has to be both distributed and synchronized across the entire system. Communication is performed asynchronously.
For certain functions that require read-only access to information, direct requests have to be made between the remote systems, using synchronous RFC, or, if this is not available, CPI-C programs. The function modules and CPI-C programs are written as required for each application.
Summary
There are both technical and business-related benefits to be realized from the distribution of applications in an integrated network.
State-of-the-art communication technology and the client/server architecture have made the distribution of standard software technically possible.
Distributed databases do not represent a good solution for the distribution of control data, master data and transaction data.
Asynchronous exchange of data with a measure of data redundancy is the best solution utilizing today's technology.
The goal of ALE is to enable data exchange between R/3-R/3, R/2- R/3 and R/3-non-SAP systems.
Control data, master data and transaction data is transmitted.
ALE also supports release upgrades and customer modifications.
ALE allows a wide range of customer-specific field choices in the communication.
IDocs (Intermediate Documents) are used for the asynchronous communication.
Allowance is made for distribution in the various applications of the R/3 System.
The application initiates the distribution of the data.
ALE and EDI complement each other.
OUT BOUND PROCESING
In the output processing one of the function modules of the application creates an IDoc, the so-called master IDoc. This IDoc is sent to the ALE layer where the following processing steps are applied:
• receiver determination, if this has not already been done by the application
• data selection
• segment filtering
• field conversion
• version change
The resulting IDocs (it is possible that several IDocs could be created in the receiver determination) are referred to as communication IDocs and are stored in the database. The dispatch control then decides which of these IDocs should be sent immediately. These are passed to the communications layer and are sent either using the transactional Remote Function Call (RFC) or via file interfaces (e.g. for EDI).
If an error occurs in the ALE layer, the IDoc containing the error is stored and a workflow is created. The ALE administrator can use this workflow to process the error.
OUT BOUND PROCESING STEP BY STEP
Receiver Determination
An IDoc is similar to a normal letter in that it has a sender and a receiver. If the receiver has not been explicitly identified by the application, then the ALE layer uses the customer distribution model to help determine the receivers for the message.
The ALE layer can find out from the model whether any distributed systems should receive the message and, if so, then how many. The result may be that one, several or no receivers at all are found.
For each of the distributed systems that have been ascertained to be receiver systems, the data that is specified by the filter objects in the customer distribution model is selected from the master IDoc. This data is then used to fill an IDoc, and the appropriate system is entered as receiver.
Segment Filtering
Individual segments can be deleted from the IDoc before dispatch by selecting Functions for the IDoc processing ® Settings for filtering in ALE Customizing. The appropriate setting depends on the sending and receiving logical R/3 System.
Field Conversion
Receiver-specific field conversions are defined under Functions for the IDoc processing ® Conversions in ALE Customizing.
General rules can be specified for field conversions; these are important for converting data fields to exchange information between R/2 and R/3 Systems. For example, the field "plant" can be converted from a 2 character field to a 4 character field.
The conversion is done using general EIS conversion tools (Executive Information System).
IDoc Version Change
SAP ensures that ALE functions between different R/3 System releases. By changing the IDoc format you can convert message types of different R/3 releases. SAP Development use the following rules when converting existing message types:
• Fields may be appended to a segment type;
• Segments can be added;
ALE Customizing keeps a record of which version of each message type is in use for each receiver. The correct version of the communication IDoc is created in the ALE output.
Dispatch Control
Controlling the time of dispatch:
The IDocs can either be sent immediately or in the background processing. This setting is made in the partner profile.
If the IDoc is to be dispatched in batch, a job has to be scheduled. You can chose the execution frequency. (e.g. daily, weekly).
Controlling the amount of data sent:
• IDocs can be dispatched in packets. To define a packet size appropriate for a specific partner, select Communication ® Manual maintenance of partner profile ® Maintain partner profile in ALE Customizing.
Mass Processing of Idocs
Mass processing refers to bundles of IDoc packets, which are dispatched and processed by the receiving R/3 System. Only one RFC call is needed to transfer several IDocs. Performance is considerably better when transferring optimal packet sizes.
To define a mass processing parameter, select Communication ® Manual maintenance of partner profile ® Maintain partner profile. For a message type the parameters packet size and output mode can be defined.
If the output mode is set to "Collect IDocs", outbound IDocs of the same message type and receiver are sent in a scheduled background job or in the BALE transaction in appropriately sized IDoc packets. The IDocs can be dispatched in batch or in the BALE transaction code.
Some distribution scenarios cannot support mass processing of inbound IDoc packets. This is especially true if the application sending the IDocs uses the ABAP/4 command CALL TRANSACTION USING. In this case the outbound parameter PACKETSIZE must be set to "1".
To get a list of function modules that can be mass processed, select Enhancements ® Inbound ® specify inbound module in ALE Customizing. INPUTTYP is "0".
INBOUND PROCESING
After an IDoc has been successfully transmitted to another system, inbound processing is carried out in the receiver system, involving the following steps in the ALE layer:
• segment filtering
• field conversion
• data transfer to the application
There are three different ways of processing an inbound IDoc:
• A function module can be called directly (standard setting),
• A workflow can be started
• A work item can be started
INBOUND PROCESING STEP BY STEP
Segment Filtering
Segment filtering functions the same way in inbound processing as in outbound processing.
Field Conversion
Specific field conversions are defined in ALE Customizing.
The conversion itself is performed using general conversion tools from the EIS area (Executive Information System).
Generalized rules can be defined. The ALE implementation guide describes how the conversion rules can be specified.
One set of rules is created for each IDoc segment and rules are defined for each segment field.
The rules for converting data fields from an R/2-specific format to an R/3 format can be defined in this way. An example of this R/2 - R/3 conversion is the conversion of the plant field from a 2 character field to a 4 character field.
Input Control
When the IDocs have been written to the database, they can be imported by the receiver application.
IDocs can be passed to the application either immediately on arrival or can follow in batch.
You can post an inbound IDoc in three ways:
1. by calling a function module directly:
- A function is called that imports the IDoc directly. An error workflow will be started only if an error occurs.
2. by starting a SAP Business Workflow. A workflow is the sequence of steps to post an IDoc.
- Workflows for ALE are not supplied in Release 3.0.
3. by starting a work item
- A single step performs the IDoc posting.
The standard inbound processing setting is that ALE calls a function module directly. For information about SAP Business Workflow alternatives refer to the online help for ALE programming.
You can specify the people to be notified for handling IDoc processing errors for each message type in SAP Business Workflow.
Repeated Attempts to Pass the Idoc to the Aplication
If the IDoc could not be passed to the application successfully (status: 51 - error on handover to application), then repeated attempts may be made with the RBDMANIN report.
This functionality can be accessed through the menu: Logistics ® Central functions ® Distribution and then Period. work ® IDoc, ALE input
Selections can be made according to specific errors. Therefore this report could be scheduled as a periodic job that collects IDocs that could not be passed to the applications because of a locking problem.
Error Handling in ALE Ibound Processing
The following is a description of how an error that occurs during ALE processing is handled:
• The processing of the IDoc causing the error is terminated.
• An event is triggered.
• This event starts an error workitem:
- The employees responsible will find a workitem in their workflow inboxes.
- An error message is displayed when the workitem is processed.
- The error is corrected in another window and the IDoc can then be resubmitted for processing.
- If the error cannot be corrected, the IDoc can be marked for deletion.
Once the IDoc has been successfully imported, an event is triggered that terminates the error workitem. The workitem then disappears from the inbox.
Objects and Standard Tasks
Message Type Standard Task ID of Standard Task
BLAOCH 7975 BLAOCH_Error
BLAORD 7974 BLAORD_Error
BLAREL 7979 BLAREL_Error
COAMAS Keine
COELEM Keine
COPAGN 8062 COPAGN_Error
COPCPA 500002 COPCPA_Error
COSMAS 8103 COSMAS_Error
CREMAS 7959 CREMAS_Error
DEBMAS 8039 DEBMAS_Error
EKSEKS 8058 EKSEKS_Error
FIDCMT 8104 FIDCMT_Error
FIROLL 8113 FIROLL_Error
GLMAST 7950 GLMAST_Error
GLROLL 7999 GLROLL_Error
INVCON 7932 INVCON_Error
INVOIC 8057 INVOIC_MM_Er
MATMAS 7947 MATMAS_Error
ORDCHG 8115 ORDCHG_Error
ORDERS 8046 ORDERS_Error
ORDRSP 8075 ORDRSP_Error
SDPACK Keine
SDPICK 8031 SDPICK_Error
SISCSO 8059 SISCSO_Error
SISDEL 8060 SISDEL_Error
SISINV 8061 SISINV_Error
SOPGEN 8063 SOPGEN_Error
WMBBIN 8047 WMBBIN_Error
WMCATO 7968 WMCATO_Error
WMCUST 8049 WMCUST_Error
WMINFO 8032 WMINFO_Error
WMINVE 7970 WMINVE_Error
WMMBXY 8009 WMMBXY_Error
WMSUMO 8036 WMSUMO_Error
WMTOCO 7972 WMTOCO_Error
WMTORD 8013 WMTORD_Error
WMTREQ 8077 WMTREQ_Error
COSFET COSFET_Error
CREFET CREFET_Error
DEBFET DEBFET_Error
GLFETC GLFETC_Error
MATFET MATFET_Error
EDI Message Types
Message Type Standard Task Functional Area
DELINS 8000 DELINS_Error
EDLNOT 8065 EDLNOT_error
INVOIC 8056 INVOIC_FI_Er
REMADV 7949 REMADV_Error
ALE QUICK START
This documentation describes how to configure a distribution in your R/3 Systems using Application Link Enabling (ALE). You will learn how to create a message flow between two clients and how to distribute materials. You will get familiar with the basic steps of the ALE configuration.
To set up and perform the distribution, proceed as follows:
1. Setting Up Clients
2. Defining A Unique Client ID
3. Defining Technical Communications Parameters
4. Modeling the Distribution
5. Generating Partner Profiles in the Sending System
6. Distributing the Customer Model
7. Generating Partner Profiles in the Receiving System
8. Creating Material Master Data
9. Sending Material Master Data
10.Checking Communication .
1. Setting Up Clients :
You must first set up two clients to enable communication. The two clients may be located on the same physical R/3 System or on separate systems.
You can either use existing clients or you can create new clients by making copies of existing ones (for example, a copy of client 000 or a client of the International Demo System (IDES)). To create new clients, you use the Copy source client function. You will find this function in the Customizing (Tools ® Business Engineering ® Customizing) under Basic functions ® Set up clients. Here you will also find additional information on setting up the clients.
Example: Clients 100 and 200 are available. Both are copies of client 000.
2. Defining A Unique Client ID :
To avoid any confusion, it is necessary for participating systems in a distributed environment to have an unique ID. The name of the "logical System" is used as the unique ID. This name is assigned explicitly to one client on an R/3 System.
When you have set up two clients for the exercise, you must tell them which logical systems exist in the distributed environment and what the description of their own client is. You will find the functions you require in the Customizing for ALE under Basic configuration ® Set up logical system.
Example : Client 100 is described as logical system LOGSYS0100.
Client 200 is described as logical system LOGSYS0200.
To maintain the logical systems in the distributed environment, choose Maintain logical systems, and
Execute the function and enter a logical system (LOG. SYSTEM) and a short text for each of your clients.
Save your entries.
When using two clients in different systems, make sure that you maintain identical entries in both systems. When using two clients in one physical R/3 System, you have to make the settings only once, since the entries are client-independent.
Log. System Short text
LOGSYS0100 System A, client 100
LOGSYS0200 System B, client 200
Allocate the corresponding logical systems to both clients using the
Allocate logical system to the client function:
Execute the function in each of the two clients.
In the view, double-click on the corresponding client.
In the Logical system field, enter the logical system name to be assigned to the indivdual client.
Save your entry.
In client Logical system
100 LOGSYS0100
200 LOGSYS0200
3.Defining Technical Communications Parameters
For the two logical systems to be able to communicate with one another, each must know how to reach the other technically. This information is found in the RFC destination.
On each of the two clients, you must maintain the RFC destination for the other logical system. You will find the function you require in the Customizing for ALE under the item Communication ® Define RFC destination.
Execute the function.
Choose Create.
Define the RFC destination:
- For the name of the destination, use the name of the logical system which is to refer to the destination (use UPPERCASE letters).
In client 100 you maintain the RFC destination LOGSYS0200.
In client 200 you maintain the RFC destination LOGSYS0100.
- As Connection type, choose 3.
- Enter a description of the RFC destination.
'RFC destination for the logical system LOGSYS0200' as a description of destination LOGSYS0200.
- As logon parameters, enter the logon language (for example, E), the logon client (for example, 200 for LOGSYS0200) and the logon user (user ID with target system password).
- Choose Enter.
- Enter the target machine and the system number:
The target machine indicates which receiving system application server is to handle communication. You can enter the specifications as UNIX host name, as host name in DNS format, as IP address or as SAP router name.
If you use SAP Logon, you can retrieve the information via Server selection ® Servers. Choose the corresponding SAP System ID and then OK. The system displays a list of all available application servers.
The system number indicates the service used (TCP service, SAP system number). When using SAP Logon, you can get the system number by selecting the system on the inital screen and then choosing EDIT.
- Save your entries.
- After saving the RFC destination, you can use Test connection to test the connection, and attempt a remote logon via Remote Login. If you succeed, the system displays a new window of the other system. Choose System ® Status... to check that you are in the correct client.
Define RFC Destination :
In this section, you define the technical parameters for the RFC destinations.
The Remote Function Call is controlled via the parameters of the RFC destination.
The RFC destinations must be maintained in order to create an RFC port.
The name of the RFC destination should correspond to the name of the logical system in question.
The following types of RFC destinations are maintainable:
• R/2 links
• R/3 links
• internal links
• logical destinations
• CMC link
• SNA/CPI-C connections
• TCP/IP links
• links of the ABAP/4 drivers
Example :
1. Enter the following parameters for an R/3 link:
- name for RFC destination: S11BSP001
- link type: 3 (for R/3 link)
- target machine: bspserver01
- system number: 11
- user in target machine: CPIC
- password, language and target client.
Standard settings
In the standard system, no RFC destinations are maintained.
Activities
1. Click on one the categories (for example, R/3 links) and choose Edit -> Create;
2. Enter the required parameters dependent on the type.
3. For an R/3 link, that is, for example, the name of the RFC destination, the name of the partner machine, logon parameter (see example).
For an R/2 connection select the option 'Password unlocked' in the log-on parameters. To test an R/2 connection you cannot use the transaction connection test, you have to use Report ACPICT1 which sets up a test connection to client 0 of the host destination. Select the check boxes for the parameters ABAP and CONVERT.
Processing RFCs with errors
If errors occur in a Remote Function Call, these are processed in the standard in the single error processing. A background job is scheduled for each RFC that resulted in an error, and this background job keeps restarting the RFC until the RFC has been processed successfully. In the case that the connection to the recipient system has been broken, this can mean that a very large of background jobs gets created that will represent a considerable additional load on the sending system.
You should always use the collective error processing in productive operation so as to improve the system performance. This will not automatically re-submit the RFC immediately, but a periodically scheduled background job will collect together all the RFCs that failed and will re-start them as a packet. This helps to reduce the number of background jobs created. This can be done both for R/3 connections and for TCP/IP connections.
To set up the collective error processing proceed as follows:
• Change the RFC destination
• Select the Destination -> TRFC options function from the menu.
• Enter the value 'X' into the 'Suppress backgr. job in case of comms. error' field.
Perform the error handling as follows:
• Start the 'Transactional RFC' monitor (menu: Logistics -> Central functions -> Distribution -> Monitoring -> Transactional RFC)
• Select the Edit -> Select.FM execute function.
For the error handling you should schedule a periodic background job that regularly does this.
Train the error handling for errors in the Remote Function Call before the prodictive start.
Further notes
The 'SAP*' user may not be used on the target machine for Remote Function Calls.
Notes on the transport
The maintenance of the RFC destination is not a part of the automatic transport and correction system. Therefore the setting has to be made manually on all systems.
Saturday, October 18, 2008
SAP ABAP ALE IDOC'S
IDoc Interface / Electronic Data Interchange
Purpose
The IDoc Interface is used to exchange business data between two different systems.
The IDoc interface consists of the definition of a data structure and the processing logic for this data structure.
The data structure is the IDoc. The systems involved must both recognize the data format used to exchange the data. IDocs allow exception handling to be defined within the R/3 System via SAP Business Workflow, without the data having to be available as an SAP application document.
You require the IDoc Interface in the following scenarios:
• Electronic Data Interchange (EDI)
• Application Link Enabling (ALE)
• Connection of any other business application systems (for example, PC applications, external workflow tools) via IDoc.
Features
For functions performed, all those from the initial node of the IDoc interface are displayed: From the R/3 initial screen choose Tools Business Communication IDoc IDoc Basis ().
Processing IDocs
This section describes the possible paths in inbound and outbound processing and the status processing. It is intended for administrators and also the end users.
Configuring ports
The technical linkage to the external system and the operating system level is described here. Port configuration is the basic prerequisite for data exchange with the external system. This section is intended for administrators.
Defining partner
A further prerequisite for data exchange is the partner profiles: Here, it is determined who can exchange which messages via which port with the R/3 System. This section is intended for administrators.
Processing tests
The IDoc interface provides tools for testing IDoc processing. Tests should be carried out both when new messages are used and for new definitions of IDoc types. This section is intended for administrators.
Monitoring
Both passive (processing display) and active monitoring (sending of warnings and advice) is documented. The section is intended for administrators and also the end users of the application.
Archiving IDocs
The archiving possibilities of IDocs are described here . This section is intended for administrators.
Structure, documentation and definition of IDoc types
The possibilities for customer enhancement of IDoc types are described here. This section is intended for R/3 developers and administrators.
General Configuration
IDoc administration: User parameter
This section describes those parameters from the IDoc administration that are regularly changed for configuration when the system is running. It is naturally intended for administrators.
Additional settings
You still have additional possibilities to configure the working environment of your IDoc interface, although in general this is not necessary. These possibilities are listed here. This section is intended for administrators.
Processing IDocs
Use
The business data is saved in IDoc format in the IDoc interface and is forwarded as IDocs. If an error occurs, exception handling is triggered via workflow tasks. The agents who are responsible for these tasks and have the relevant authorizations are defined in the IDoc interface.
Features
The IDoc interface supports three types of data flow with the external system:
• Outbound processing
IDocs are transferred to a receiving system from your SAP System.
• Inbound processing
IDocs are transferred to your SAP System from an upstream system.
• Status processing
The receiving system confirms the processing status of outbound IDocs to your SAP System.
Control records and data records are sent for IDoc inbound processing and IDoc outbound processing. Status records are sent in the status confirmation data flow (exception: status confirmation via the specific IDoc type SYSTAT01).
Exception handling functions are implemented when errors occur.
Role Resolution in Exception Handling
This section describes how the agents responsible for a work item are determined in the IDoc interface.
Communication with Older Releases
Additional customizing settings may be required.
Outbound Processing under Message Control (MC)
Use
Messages, for example purchase orders, can be found and processed via the Message Control module (MC) in SD and MM. In the case of IDoc processing, that means that the application data is written to IDocs.
Prerequisites
Setting up IDoc processing always requires you to define your partner. In particular for MC, you must assign the application and the MC output type uniquely to an IDoc type in partner profiles. You do this with the additional outbound parameters under MC.
Activities
• The Message Control module "finds" one or more messages by selecting those that match the relevant business process from a set of predefined messages. The messages are defined in the application in so-called condition tables. The messages found are "proposed" by the MC: That can be several per document. In many applications you can view and modify ("process") messages before you release the data, post the document and send the messages as IDocs.
In the specified case (message processing through IDoc dispatch) the system additionally checks messages found to determine whether the message partner was processed as a partner in the IDoc interface. The message is only proposed if this is the case, and can then be further processed. Many applications provide determination analysis, which helps you to trace message determination and locate possible errors.
• The Message Control module can process the messages immediately (after the application document has been updated). You can also process the messages found manually or in the background at a predefined time. Since you can also define the time at which IDocs are to be generated by the IDoc interface, you should combine these two times. These combinations are described in the following section: Procedure
An order for the vendor VEND is to be created in Purchasing. This order is to be sent via an EDI subsystem after being written as an IDoc of type ORDERS01. In order to do this, define the output type "NEU" (new) for VEND in purchasing master data and assign the Message Control dispatch time "4" (immediately with application update) and the transmission medium "EDI".
Choose the output mode "Transfer IDoc immediately" and "Start subsystem immediately" for VEND in the partner profiles of the IDoc interface and assign the logical message ORDERS to the combination "Application: Purchasing orders", "Output type: NEU" (new). IDoc type ORDERS01 is assigned to this logical message.
Outbound Processing under Message Control: Procedure
Message determination: Call the master data from the application and create the message as a message- or condition record, that is to say, you define the conditions under which the message is found and proposed, as well as the message properties. For example, you can enter the purchasing organization and the business partner as the conditions and the output medium (in this case 6 for EDI), dispatch time and language in which the message is to be sent as the output properties.
Message processing through IDoc dispatch: The messages are sent by the Message Control module as defined in the condition record, especially with regard to the selected dispatch time. You must also define a dispatch time ("output mode") in the partner profiles of the IDoc interface: standard combinations of the two times are shown in the table below. The Message Control parameters from the partner profiles must also match the corresponding fields in the output type. These parameters include:
Application
Partner
Partner function
Output type
Dispatch time combinations for the Message Control module and IDoc interface and the EDI equivalents
MC: Dispatch time IDoc interface: Output mode EDI equivalent
4 (= immediately) Send IDoc immediately
Start subsystem Real time
1 (= send with next selection run) Send IDoc immediately
Start subsystem Fast batch
1 Collect IDocs
Start subsystem Batch
1 Collect IDocs Do not
start subsystem Batch
If you specify that the subsystem (= follow-on system) is not to be started in the partner profiles, the receiving system determines the dispatch time in accordance with the time plan set in the system, that is to say you do not have any control over when the IDoc arrives at the target system.
Outbound Processing under Message Control: Technical Implementation
For a detailed description of the Message Control module, please refer to the documentation under CA Message Control .
• Message determination: The conditions, under which a message is to be found, are stored in the condition tables . These tables are read in an access sequence . The condition tables also contain the key fields for the application, that is to say, the fields which the application uses to access the condition records (for example the "purchasing organization" and "vendor" application fields in Purchasing). The condition tables are assigned to an output type (for example "NEU" (new) for a purchase order from Purchasing). The output types are combined in Procedures , which are assigned to the application (key, for example purchase order).
This organizational structure allows message determination to run in a structured manner and under complex conditions. The output types and tables and the access sequences and procedures are already defined in Customizing for the relevant application.
The output type is sometimes also referred to as the condition type.
• Message processing through IDoc dispatch: the central selection program of the Message Control module, RSNAST00, locates and triggers the form routine EDI_PROCESSING in the program RSNASTED in table TNAPR for the selected output type. EDI_PROCESSING reads the partner profiles and uses the process code to determine the function module which is to generate the IDoc. The process code also determines the type of further processing, for example whether the IDocs are to be processed by the ALE service.
The function modules for generating the IDocs are usually called IDOC_OUTPUT_, where represents the relevant message type. Depending on the output mode, the generated IDocs are either collected or forwarded for immediate dispatch. If the IDocs are collected, the report RSEOUT00 must be scheduled in order to forward the IDocs for dispatch.
Direct Outbound Processing: Procedure
Choose the relevant send transaction in the application and enter the parameters
accordingly. Make sure that the specified communication parameters (such as the target system) are also maintained as a port in the partner profiles of the IDoc interface. In ALE scenarios a "tRFC" port type should be entered and the partner should be an "LS" type (for "logical system").
Direct Outbound Processing: Implementation for ALE :
The way in which the IDoc is generated depends on the respective application. The following is an example of an ALE scenario in which a function module is responsible for generating the IDocs.
The function module is called in the application transaction. The function module generates a so-called master IDoc, which is transferred to the administration module MASTER_IDOC_DISTRIBUTE, which checks the control record and then calls the function module COMMUNICATION_IDOC_CREATE. This module "filters" the master IDoc (that is to say removes any data which is not required for communication).
This "filtered" IDoc is referred to as the communication IDoc and is forwarded for further processing to the function module EDI_OUTPUT_NEW by MASTER_IDOC_DISTRIBUTE.
Inbound Processing
Use
In inbound processing, IDocs are transferred to the interface and stored in the R/3 System. The document data is generated in a second step, also in the course of a workflow.
Features
The upstream system transfers an IDoc to the IDoc interface via the R/3 System port. For this reason, you do not have to specify a port in the inbound partner profiles; the IDoc interface only has to "recognize" the upstream system as a port. A port definition, which provides a unique ID for the upstream system, must be available for the port. The technical parameters of this port definition can (and usually are) overwritten by the upstream system.
The IDoc is "accepted", that is, saved in the database, if the upstream system is recognized. If your partner is defined with the corresponding message in your partner profiles, the IDoc is then processed further. This is done independently in a second step. This ensures that the external system can receive the data quickly and reliably (automatically).
The following paths are available for further processing:
• The direct path via a function module which transfers the IDoc data to the corresponding application document.
• The indirect path via SAP Business Workflow (single- or multistep task). When an IDoc is received, a work item is created as an instance of the corresponding task. The work item appears in the integrated inbox of the selected agent. For further information on SAP Business Workflow see Basis Business Management SAP Business Workflow.
IDoc type TXTRAW02 is processed via the single-step task TS30000008: A mail is sent to the SAPoffice user (or the organizational unit) that is entered as the recipient in segment E1TXTAD. If this segment is missing, the permitted agent is determined from the partner profiles as the recipient. The mail contains the text from the IDoc data records. You can also send mail attributes such as priority or "executability".
The indirect path in Release 2.1/2.2 is implemented via process technology. This technology is no longer supported.
Activities
Inbound processing: Procedure
Inbound processing: Implementation .
Inbound Processing: Procedure
Purpose
Therefore, you must always configure inbound processing when you want to implement new business processes where data will be received by IDoc. An example is EDI inbound processing of standard orders.
Prerequisites
You must only activate the event-receiver linkage for the IDoc interface once, because an event is always triggered when an IDoc is received (exception: port type "tRFC"). This takes place in Customizing, activity Activate event-receiver linkage for IDoc inbound processing.
Process flow
The inbound IDoc is linked to the required processing type via the process code in the partner profiles. You can decide whether a workflow or a function module is triggered when an IDoc is received.
The process codes supplied with the standard system are already assigned to workflows or function modules. You can display this assignment: from the initial screen of the IDoc interface (transaction WEDI), choose Control Process code inbound. This is also the initial screen for new assignments when you want to define new IDoc types or processing types. For more information, see define new IDoc types
A vendor receives a purchase order for a material via an IDoc of type ORDERS01. The vendor has assigned the function module IDOC_INPUT_ORDERS, which converts the IDoc data to the corresponding application data, to the ORDERS message via the process code ORDE. The vendor, therefore, selects the direct path via a function module.
There are IDoc types for which inbound processing only takes place in Basis, for example TXTRAW02. These IDoc types are only processed by workflow. The corresponding tasks are grouped together in task group TG70000016. Inbound processing by workflow in logistics is located in task group TG20000011. Task groups make the search for tasks in the Business Workflow Explorer (Area menu SWLD) easier.
For exception handling in inbound processing you must assign the possible agents to the corresponding tasks. You have two alternatives:
•You must classify all tasks as general tasks in IDoc Customizing.
•You maintain the allocation for each individual task via transaction PFTC. The section on Exception handling: procedure describes which tasks are used.
Purpose
The IDoc Interface is used to exchange business data between two different systems.
The IDoc interface consists of the definition of a data structure and the processing logic for this data structure.
The data structure is the IDoc. The systems involved must both recognize the data format used to exchange the data. IDocs allow exception handling to be defined within the R/3 System via SAP Business Workflow, without the data having to be available as an SAP application document.
You require the IDoc Interface in the following scenarios:
• Electronic Data Interchange (EDI)
• Application Link Enabling (ALE)
• Connection of any other business application systems (for example, PC applications, external workflow tools) via IDoc.
Features
For functions performed, all those from the initial node of the IDoc interface are displayed: From the R/3 initial screen choose Tools Business Communication IDoc IDoc Basis ().
Processing IDocs
This section describes the possible paths in inbound and outbound processing and the status processing. It is intended for administrators and also the end users.
Configuring ports
The technical linkage to the external system and the operating system level is described here. Port configuration is the basic prerequisite for data exchange with the external system. This section is intended for administrators.
Defining partner
A further prerequisite for data exchange is the partner profiles: Here, it is determined who can exchange which messages via which port with the R/3 System. This section is intended for administrators.
Processing tests
The IDoc interface provides tools for testing IDoc processing. Tests should be carried out both when new messages are used and for new definitions of IDoc types. This section is intended for administrators.
Monitoring
Both passive (processing display) and active monitoring (sending of warnings and advice) is documented. The section is intended for administrators and also the end users of the application.
Archiving IDocs
The archiving possibilities of IDocs are described here . This section is intended for administrators.
Structure, documentation and definition of IDoc types
The possibilities for customer enhancement of IDoc types are described here. This section is intended for R/3 developers and administrators.
General Configuration
IDoc administration: User parameter
This section describes those parameters from the IDoc administration that are regularly changed for configuration when the system is running. It is naturally intended for administrators.
Additional settings
You still have additional possibilities to configure the working environment of your IDoc interface, although in general this is not necessary. These possibilities are listed here. This section is intended for administrators.
Processing IDocs
Use
The business data is saved in IDoc format in the IDoc interface and is forwarded as IDocs. If an error occurs, exception handling is triggered via workflow tasks. The agents who are responsible for these tasks and have the relevant authorizations are defined in the IDoc interface.
Features
The IDoc interface supports three types of data flow with the external system:
• Outbound processing
IDocs are transferred to a receiving system from your SAP System.
• Inbound processing
IDocs are transferred to your SAP System from an upstream system.
• Status processing
The receiving system confirms the processing status of outbound IDocs to your SAP System.
Control records and data records are sent for IDoc inbound processing and IDoc outbound processing. Status records are sent in the status confirmation data flow (exception: status confirmation via the specific IDoc type SYSTAT01).
Exception handling functions are implemented when errors occur.
Role Resolution in Exception Handling
This section describes how the agents responsible for a work item are determined in the IDoc interface.
Communication with Older Releases
Additional customizing settings may be required.
Outbound Processing under Message Control (MC)
Use
Messages, for example purchase orders, can be found and processed via the Message Control module (MC) in SD and MM. In the case of IDoc processing, that means that the application data is written to IDocs.
Prerequisites
Setting up IDoc processing always requires you to define your partner. In particular for MC, you must assign the application and the MC output type uniquely to an IDoc type in partner profiles. You do this with the additional outbound parameters under MC.
Activities
• The Message Control module "finds" one or more messages by selecting those that match the relevant business process from a set of predefined messages. The messages are defined in the application in so-called condition tables. The messages found are "proposed" by the MC: That can be several per document. In many applications you can view and modify ("process") messages before you release the data, post the document and send the messages as IDocs.
In the specified case (message processing through IDoc dispatch) the system additionally checks messages found to determine whether the message partner was processed as a partner in the IDoc interface. The message is only proposed if this is the case, and can then be further processed. Many applications provide determination analysis, which helps you to trace message determination and locate possible errors.
• The Message Control module can process the messages immediately (after the application document has been updated). You can also process the messages found manually or in the background at a predefined time. Since you can also define the time at which IDocs are to be generated by the IDoc interface, you should combine these two times. These combinations are described in the following section: Procedure
An order for the vendor VEND is to be created in Purchasing. This order is to be sent via an EDI subsystem after being written as an IDoc of type ORDERS01. In order to do this, define the output type "NEU" (new) for VEND in purchasing master data and assign the Message Control dispatch time "4" (immediately with application update) and the transmission medium "EDI".
Choose the output mode "Transfer IDoc immediately" and "Start subsystem immediately" for VEND in the partner profiles of the IDoc interface and assign the logical message ORDERS to the combination "Application: Purchasing orders", "Output type: NEU" (new). IDoc type ORDERS01 is assigned to this logical message.
Outbound Processing under Message Control: Procedure
Message determination: Call the master data from the application and create the message as a message- or condition record, that is to say, you define the conditions under which the message is found and proposed, as well as the message properties. For example, you can enter the purchasing organization and the business partner as the conditions and the output medium (in this case 6 for EDI), dispatch time and language in which the message is to be sent as the output properties.
Message processing through IDoc dispatch: The messages are sent by the Message Control module as defined in the condition record, especially with regard to the selected dispatch time. You must also define a dispatch time ("output mode") in the partner profiles of the IDoc interface: standard combinations of the two times are shown in the table below. The Message Control parameters from the partner profiles must also match the corresponding fields in the output type. These parameters include:
Application
Partner
Partner function
Output type
Dispatch time combinations for the Message Control module and IDoc interface and the EDI equivalents
MC: Dispatch time IDoc interface: Output mode EDI equivalent
4 (= immediately) Send IDoc immediately
Start subsystem Real time
1 (= send with next selection run) Send IDoc immediately
Start subsystem Fast batch
1 Collect IDocs
Start subsystem Batch
1 Collect IDocs Do not
start subsystem Batch
If you specify that the subsystem (= follow-on system) is not to be started in the partner profiles, the receiving system determines the dispatch time in accordance with the time plan set in the system, that is to say you do not have any control over when the IDoc arrives at the target system.
Outbound Processing under Message Control: Technical Implementation
For a detailed description of the Message Control module, please refer to the documentation under CA Message Control .
• Message determination: The conditions, under which a message is to be found, are stored in the condition tables . These tables are read in an access sequence . The condition tables also contain the key fields for the application, that is to say, the fields which the application uses to access the condition records (for example the "purchasing organization" and "vendor" application fields in Purchasing). The condition tables are assigned to an output type (for example "NEU" (new) for a purchase order from Purchasing). The output types are combined in Procedures , which are assigned to the application (key, for example purchase order).
This organizational structure allows message determination to run in a structured manner and under complex conditions. The output types and tables and the access sequences and procedures are already defined in Customizing for the relevant application.
The output type is sometimes also referred to as the condition type.
• Message processing through IDoc dispatch: the central selection program of the Message Control module, RSNAST00, locates and triggers the form routine EDI_PROCESSING in the program RSNASTED in table TNAPR for the selected output type. EDI_PROCESSING reads the partner profiles and uses the process code to determine the function module which is to generate the IDoc. The process code also determines the type of further processing, for example whether the IDocs are to be processed by the ALE service.
The function modules for generating the IDocs are usually called IDOC_OUTPUT_
SAP - DIFFERENCE BETWEEN CONVERSION AND INTERFACE
DIFFERENCE BETWEEN CONVERSION AND INTERFACE:
A Conversion means data that is converted from one format to another format and from one system to another.
So when you first implement SAP, you are actually replacing some of your legacy systems, but you are not completely trashing the data. You still need some of that data from the systems that are being replaced. So you pull the data out of your legacy systems and put them on some files. You then want to load that data into your new SAP system.
That is when you write some programs which will read that data and load it into SAP. Imagine you had a home grown purchasing system. You are now replacing all that with SAP. But until SAP goes live, you want to keep using your home grown purchasing system.
So during go live, you want to transfer the POs from your legacy system to SAP. Now a PO in your legacy system may not have the same fields as a PO in SAP. So you convert the data.
Ex: BDC,LSMW
Interfacing is connecting two or more different entities. In our case, it is connecting one or more systems with SAP. Now extending our previous example, you are replacing some legacy applications but there are some applications that you don't want to replace yet.
You need to somehow pass data back and forth between SAP and these remaining systems. Data may be going one way or the other way or both ways. You will still need to do some data transformations/translations etc to make the data understandable to the receiving system.
This will continue as long as you want to keep the systems running alongside SAP.
Ex: idoc,bapi
In short, conversions are written to load data into SAP onetime. These are typically file based.
Interfaces are written to exchange/update/send/receive data between SAP and other systems on an ongoing basis. These can be in many forms, file based, idoc based, real time(business connector, XI etc are useful in this), xml, and the list goes on.
A Conversion means data that is converted from one format to another format and from one system to another.
So when you first implement SAP, you are actually replacing some of your legacy systems, but you are not completely trashing the data. You still need some of that data from the systems that are being replaced. So you pull the data out of your legacy systems and put them on some files. You then want to load that data into your new SAP system.
That is when you write some programs which will read that data and load it into SAP. Imagine you had a home grown purchasing system. You are now replacing all that with SAP. But until SAP goes live, you want to keep using your home grown purchasing system.
So during go live, you want to transfer the POs from your legacy system to SAP. Now a PO in your legacy system may not have the same fields as a PO in SAP. So you convert the data.
Ex: BDC,LSMW
Interfacing is connecting two or more different entities. In our case, it is connecting one or more systems with SAP. Now extending our previous example, you are replacing some legacy applications but there are some applications that you don't want to replace yet.
You need to somehow pass data back and forth between SAP and these remaining systems. Data may be going one way or the other way or both ways. You will still need to do some data transformations/translations etc to make the data understandable to the receiving system.
This will continue as long as you want to keep the systems running alongside SAP.
Ex: idoc,bapi
In short, conversions are written to load data into SAP onetime. These are typically file based.
Interfaces are written to exchange/update/send/receive data between SAP and other systems on an ongoing basis. These can be in many forms, file based, idoc based, real time(business connector, XI etc are useful in this), xml, and the list goes on.
BAPI AND IDOC ALE
ALE
ALE is SAP proprietary technology that enables data communications between two or more SAP R/3 systems and/or R/3 and external systems. When a new enterprise resource planning (ERP) solution such as R/3 is implemented, companies have to interface the ERP system with legacy systems or other ERP systems.
ALE provides intelligent mechanisms where by clients can achieve integration as well as distribution of applications and data.
ALE technology facilitates rapid application prototyping and application interface development, thus reducing implementation time.
The ALE components are inherently integrated with SAP applications and are robust, leading to a highly reliable system.
ALE comes with application distribution/integration scenarios as well as a set of tools, programs, data definitions, and methodologies that you can easily configure to get an interface up and running.
BAPI
BAPIs provide a stable, standardized method for third-party applications and components to integrate into the Business Framework. These interfaces are being specified as part of SAP's initiative with customers, partners and leading standards organizations. Also, SAP has implemented the emerging Object Application Group (OAG) specifications with BAPIs.
Pros and Cons for both BAPI and Call Transaction
BAPI
One of the big plusses for BAPIs is that the interface and function are not supposed to change. This is a big plus when you do upgrades or hot packs because the transaction can change (format, required inputs etc) which means you then need to update the call transaction.
Some of the BAPIs are better documented and easier to use than others.
You usually need to perform the BAPI that actually does the COMMIT after you call your BAPI.
The Program coding for calling a BAPI is usually cleaner than setting up the screen flow etc for the Call Transaction.
You don't need to worry about special data circumstances interrupting the normal data flow of the screens and causing errors because of that.
BAPIs probably have better performance since they don't do the screen flow processing.
In general if the BAPI exists for the transaction you want to perform and you can figure out how to use it the BAPI is probably the best way to go.
This is just from my experience working with both BAPI and Call Transaction. I have had some very good successes with BAPIs, but very occasionally found that I could not get the BAPI to perform the update I needed.
The interface concept of the classic R/3 is based on two different strategies: Remote Function Calls (RFC) and data exchange through IDoc message documents. RFC makes direct and synchronous calls of a program in the remote system. If the caller is an external program it will call an RFC-enabled function in R/3 and if the calling program is the R/3 system it will call an RFC-function in another R/3-system or it will call a non-R/3 program through a gateway-proxy (usually rfcexec.exe).
BAPIs are a subset of the RFC-enabled function modules, especially designed as Application Programming Interface (API) to the SAP business object, or in other words: are function modules officially released by SAP to be called from external programs.
IDocs are text encoded documents with a rigid structure that are used to exchange data between R/3 and a foreign system. Instead of calling a program in the destination system directly, the data is first packed into an IDoc and then sent to the receiving system, where it is analyzed and properly processed. Therefore an IDoc data exchange is always an asynchronous process. The significant difference between simple RFC-calls and IDoc data exchange is the fact, that every action performed on IDocs are protocolled by R/3 and IDocs can be reprocessed if an error occurred in one of the message steps.
While IDocs have to be understood as a data exchange protocol, EDI and ALE are typical use cases for IDocs. R/3 uses IDocs for both EDI and ALE to deliver data to the receiving system. ALE is basically the scheduling mechanism that defines when and between which partners and what kind of data will be exchanged on a regular or event triggered basis. Such a set-up is called an ALE-scenario.
The philosophical difference between EDI and ALE can be pinned as follows: If we send data to an external partner, we generally speak of EDI, while ALE is a mechanism to reliable replicate data between trusting systems to store a redundant copy of the IDoc data.
The difference is made clear, when we think of a purchase order that is sent as an IDoc. If we send the purchase order to a supplier then the supplier will store the purchase order as a sales order. However, if we send the purchase order via ALE to another R/3 system, then the receiving system will store the purchase order also as a purchase order.
ALE is SAP proprietary technology that enables data communications between two or more SAP R/3 systems and/or R/3 and external systems. When a new enterprise resource planning (ERP) solution such as R/3 is implemented, companies have to interface the ERP system with legacy systems or other ERP systems.
ALE provides intelligent mechanisms where by clients can achieve integration as well as distribution of applications and data.
ALE technology facilitates rapid application prototyping and application interface development, thus reducing implementation time.
The ALE components are inherently integrated with SAP applications and are robust, leading to a highly reliable system.
ALE comes with application distribution/integration scenarios as well as a set of tools, programs, data definitions, and methodologies that you can easily configure to get an interface up and running.
BAPI
BAPIs provide a stable, standardized method for third-party applications and components to integrate into the Business Framework. These interfaces are being specified as part of SAP's initiative with customers, partners and leading standards organizations. Also, SAP has implemented the emerging Object Application Group (OAG) specifications with BAPIs.
Pros and Cons for both BAPI and Call Transaction
BAPI
One of the big plusses for BAPIs is that the interface and function are not supposed to change. This is a big plus when you do upgrades or hot packs because the transaction can change (format, required inputs etc) which means you then need to update the call transaction.
Some of the BAPIs are better documented and easier to use than others.
You usually need to perform the BAPI that actually does the COMMIT after you call your BAPI.
The Program coding for calling a BAPI is usually cleaner than setting up the screen flow etc for the Call Transaction.
You don't need to worry about special data circumstances interrupting the normal data flow of the screens and causing errors because of that.
BAPIs probably have better performance since they don't do the screen flow processing.
In general if the BAPI exists for the transaction you want to perform and you can figure out how to use it the BAPI is probably the best way to go.
This is just from my experience working with both BAPI and Call Transaction. I have had some very good successes with BAPIs, but very occasionally found that I could not get the BAPI to perform the update I needed.
The interface concept of the classic R/3 is based on two different strategies: Remote Function Calls (RFC) and data exchange through IDoc message documents. RFC makes direct and synchronous calls of a program in the remote system. If the caller is an external program it will call an RFC-enabled function in R/3 and if the calling program is the R/3 system it will call an RFC-function in another R/3-system or it will call a non-R/3 program through a gateway-proxy (usually rfcexec.exe).
BAPIs are a subset of the RFC-enabled function modules, especially designed as Application Programming Interface (API) to the SAP business object, or in other words: are function modules officially released by SAP to be called from external programs.
IDocs are text encoded documents with a rigid structure that are used to exchange data between R/3 and a foreign system. Instead of calling a program in the destination system directly, the data is first packed into an IDoc and then sent to the receiving system, where it is analyzed and properly processed. Therefore an IDoc data exchange is always an asynchronous process. The significant difference between simple RFC-calls and IDoc data exchange is the fact, that every action performed on IDocs are protocolled by R/3 and IDocs can be reprocessed if an error occurred in one of the message steps.
While IDocs have to be understood as a data exchange protocol, EDI and ALE are typical use cases for IDocs. R/3 uses IDocs for both EDI and ALE to deliver data to the receiving system. ALE is basically the scheduling mechanism that defines when and between which partners and what kind of data will be exchanged on a regular or event triggered basis. Such a set-up is called an ALE-scenario.
The philosophical difference between EDI and ALE can be pinned as follows: If we send data to an external partner, we generally speak of EDI, while ALE is a mechanism to reliable replicate data between trusting systems to store a redundant copy of the IDoc data.
The difference is made clear, when we think of a purchase order that is sent as an IDoc. If we send the purchase order to a supplier then the supplier will store the purchase order as a sales order. However, if we send the purchase order via ALE to another R/3 system, then the receiving system will store the purchase order also as a purchase order.
SAP ABAP MESSAGE CONTORL
Message Control is a cross application component used as a service program in several areas. The biggest application is in pricing.
The basic concept behind message control is to generate and manage outputs from an application and control their timing and medium of exchange.
The Benefits of Message Control.
• Disconnecting the process of creating an application document from the process of generating outputs.
• Automatically proposing output based on business rules specified in Message Control.
• Overriding the automatic proposal.
• Manually selecting an output.
• Generating multiple outputs.
• Controlling the timing, medium and language of the output messages.
• Retransmitting an output
• Monitoring the results of execution.
To find a complete list of applications in that currently use Message Control the T-Code is NACE.
Message control is a service module, and applications call the message control services using standard function modules of Message control. A list of applications commonly used in EDI process and enabled for Message Control follows.
• Billing
• Delivery schedule
• Purchasing
• Purchasing outline agreement
• Request for quote.
• Sales
• Shipping
• Transportation
The Message Control Components
To understand the Message Control process, it is important to clarify the terminology and identify the various components.
Output types are also called messages, message types, or condition types.
Procedures are also called message schemas.
Condition type and Condition record are two separate things.
The Message Control components
The Output type - An output type defines the characteristics and attributes of the output.
The Access Sequence – An access sequence defines a sequence in which business rules are checked for proposing an output type.
The Condition Table – The Condition table specifies the key fields for a business rule.
The Condition Record - Condition records are inserted in the condition table. Condition records contain the actual data against which the business rules are checked to propose an output.
How Message Control Works
It is a Three step process.
1. Output Proposal.
2. Output Editing.
3. Output Processing.
The basic concept behind message control is to generate and manage outputs from an application and control their timing and medium of exchange.
The Benefits of Message Control.
• Disconnecting the process of creating an application document from the process of generating outputs.
• Automatically proposing output based on business rules specified in Message Control.
• Overriding the automatic proposal.
• Manually selecting an output.
• Generating multiple outputs.
• Controlling the timing, medium and language of the output messages.
• Retransmitting an output
• Monitoring the results of execution.
To find a complete list of applications in that currently use Message Control the T-Code is NACE.
Message control is a service module, and applications call the message control services using standard function modules of Message control. A list of applications commonly used in EDI process and enabled for Message Control follows.
• Billing
• Delivery schedule
• Purchasing
• Purchasing outline agreement
• Request for quote.
• Sales
• Shipping
• Transportation
The Message Control Components
To understand the Message Control process, it is important to clarify the terminology and identify the various components.
Output types are also called messages, message types, or condition types.
Procedures are also called message schemas.
Condition type and Condition record are two separate things.
The Message Control components
The Output type - An output type defines the characteristics and attributes of the output.
The Access Sequence – An access sequence defines a sequence in which business rules are checked for proposing an output type.
The Condition Table – The Condition table specifies the key fields for a business rule.
The Condition Record - Condition records are inserted in the condition table. Condition records contain the actual data against which the business rules are checked to propose an output.
How Message Control Works
It is a Three step process.
1. Output Proposal.
2. Output Editing.
3. Output Processing.
SAP IDOC'S IN ABAP INTRODUCTION
IDocs are SAP’s file format to exchange data with a foreign system.
IDocs are an ASCII file format to exchange data between computers; the format is chosen arbitrarily .
IDocs are similar to segmented files; they are not a description language like ANSI X.12, EDIFACT or XML.
The IDoc contents are processed by function modules, which can be assigned in customizing.
IDocs are structured ASCII files (or a virtual equivalent). They are the file format used by SAP R/3 to exchange data with foreign systems.
IDocs are simple ASCII data streams. When they are stored to a disk file, the IDocs
are simple flat files with lines of text, where the lines are structured into data fields.
The typical structured file has records, each record starting with a leading string that identifies the record type. Their specification is stored in the data dictionary.
IDocs is the acronym for Interchange Document. This indicates a set of (electronic)
information which builds a logical entity. An IDoc is e.g. all the data of a single
customer in your customer master data file, or the IDoc is all the data of a single
invoice.
IDoc data is usually exchanged between systems and partners that are completely
independent. Therefore, the data should be transmitted in a format that can easily be
corrected by the computer operators. It is therefore mandatory to post the data in a
human readable form.
Nowadays, this means that data is coded in ASCII format, including numbers which
are sent as a string of figures 0 to 9. Such data can easily be read with any text editor on any computer, be it a PC, Macintosh, UNIX System, S/390 or any internet
browser.
The information which is exchanged by IDocs is called a message and the IDoc is
the physical representation of such a message. The name “messages” for the
information sent via IDocs is used in the same ways as other EDI standards. .
Everybody who has ever dealt with interface programming, will find IDocs very
much like the hierarchical data files used in traditional data exchange.
International standards like the ODETTE or VDA formats are designed in the same
way as IDocs are.
Other EDI standards like XML, ANSI X.12 or EDIFACT/UN are based on a data
description language. They differ principally from the IDocs concept, because they
use a programming language syntax (e.g. like Postscript or HTML) to embed the DATA.
The IDoc process is a straight forward communication scenario. A communication is
requested, then data is retrieved, wrapped and sent to the destination in a predefined format and envelope.
An R/3 application creates data and updates the database appropriately. An
application can be a transaction, a stand-alone ABAP Report or any tool that can
update a database within R/3.
If the application thinks that data needs to be distributed to a foreign system, it
triggers the IDoc mechanism, usually by leaving a descriptive message record in the
message table NAST.
The application then either directly calls the IDoc engine or a collector job
eventually picks up all due IDoc messages and determines what to do with them.
If the engine believes that data is ready to be sent to a partner system, then it
determines the function module which can collect and wrap the required IDoc data
into an IDoc.
In IDoc customising, you specify the name of the function module to use. This can
either be one which is predefined by R/3 standard or a user-written one.
When the IDoc is created it is stored in an R/3 table and from there it is sent to the foreign system.
If the foreign system requires a special conversion, e.g. to XML, EDIFACT or X.12
then this job needs to be done by an external converter, like the Seeburger ELKE™
system. These converters are not part of R/3.
If you have to decide on a converter solution, we strongly recommend using a plain
PC based solution. Conversion usually requires a lot of fine tuning which stands
and falls with the quality of the provided tools.
Summary
The first record in an IDoc is a control record describing the content of the data
All but the first record are data records with the same formal record structure
Every record is tagged with the segment type and followed by the segment data.
The interpretation of the segment is done by the IDoc application
Both sent and received IDocs are logged in R/3 tables for further reference and archiving purposes.
IDocs are an ASCII file format to exchange data between computers; the format is chosen arbitrarily .
IDocs are similar to segmented files; they are not a description language like ANSI X.12, EDIFACT or XML.
The IDoc contents are processed by function modules, which can be assigned in customizing.
IDocs are structured ASCII files (or a virtual equivalent). They are the file format used by SAP R/3 to exchange data with foreign systems.
IDocs are simple ASCII data streams. When they are stored to a disk file, the IDocs
are simple flat files with lines of text, where the lines are structured into data fields.
The typical structured file has records, each record starting with a leading string that identifies the record type. Their specification is stored in the data dictionary.
IDocs is the acronym for Interchange Document. This indicates a set of (electronic)
information which builds a logical entity. An IDoc is e.g. all the data of a single
customer in your customer master data file, or the IDoc is all the data of a single
invoice.
IDoc data is usually exchanged between systems and partners that are completely
independent. Therefore, the data should be transmitted in a format that can easily be
corrected by the computer operators. It is therefore mandatory to post the data in a
human readable form.
Nowadays, this means that data is coded in ASCII format, including numbers which
are sent as a string of figures 0 to 9. Such data can easily be read with any text editor on any computer, be it a PC, Macintosh, UNIX System, S/390 or any internet
browser.
The information which is exchanged by IDocs is called a message and the IDoc is
the physical representation of such a message. The name “messages” for the
information sent via IDocs is used in the same ways as other EDI standards. .
Everybody who has ever dealt with interface programming, will find IDocs very
much like the hierarchical data files used in traditional data exchange.
International standards like the ODETTE or VDA formats are designed in the same
way as IDocs are.
Other EDI standards like XML, ANSI X.12 or EDIFACT/UN are based on a data
description language. They differ principally from the IDocs concept, because they
use a programming language syntax (e.g. like Postscript or HTML) to embed the DATA.
The IDoc process is a straight forward communication scenario. A communication is
requested, then data is retrieved, wrapped and sent to the destination in a predefined format and envelope.
An R/3 application creates data and updates the database appropriately. An
application can be a transaction, a stand-alone ABAP Report or any tool that can
update a database within R/3.
If the application thinks that data needs to be distributed to a foreign system, it
triggers the IDoc mechanism, usually by leaving a descriptive message record in the
message table NAST.
The application then either directly calls the IDoc engine or a collector job
eventually picks up all due IDoc messages and determines what to do with them.
If the engine believes that data is ready to be sent to a partner system, then it
determines the function module which can collect and wrap the required IDoc data
into an IDoc.
In IDoc customising, you specify the name of the function module to use. This can
either be one which is predefined by R/3 standard or a user-written one.
When the IDoc is created it is stored in an R/3 table and from there it is sent to the foreign system.
If the foreign system requires a special conversion, e.g. to XML, EDIFACT or X.12
then this job needs to be done by an external converter, like the Seeburger ELKE™
system. These converters are not part of R/3.
If you have to decide on a converter solution, we strongly recommend using a plain
PC based solution. Conversion usually requires a lot of fine tuning which stands
and falls with the quality of the provided tools.
Summary
The first record in an IDoc is a control record describing the content of the data
All but the first record are data records with the same formal record structure
Every record is tagged with the segment type and followed by the segment data.
The interpretation of the segment is done by the IDoc application
Both sent and received IDocs are logged in R/3 tables for further reference and archiving purposes.
SAP ABAP IDOC'S OUTLOOK
IDocs are basically a small number of records in ASCII format, building a logical
entity. It makes sense to see an IDoc as a plain and simple ASCII text file, even if it
might be transported via other means.
Any IDoc consists of two sections:
the control record
which is always the first line of the file and provides the administrative information.
the data record which contains the application dependent data, as in our example below the material master data.
We will discuss the exchange of the material master IDoc MATMAS in the
paragraphs that follow..
The definition of the IDoc structure MATMAS01 is deposited in the data dictionary
and can be viewed with WE30.
The very first record of an IDoc package is always a control record. The structure of this control record is the DDic structure EDIDC and describes the contents of the data contained in the package.
The control record carries all the administrative information of the IDoc, such as its origin, its destination and a categorical description of the contents and context of the attached IDoc data. This is very much like the envelope or cover sheet that
would accompany any paper document sent via postal mail.
For R/3 inbound processing, the control record is used by the standard IDoc
processing mechanism to determine the method for processing the IDoc. This
method is usually a function module but may be a business object as well. The
processing method can be fully customised.
Once the IDoc data is handed over to a processing function module, you will no
longer need the control record information. The function modules are aware of the
individual structure of the IDoc type and the meaning of the data. In other words:
for every context and syntax of an IDoc, you would write an individual function module or business object (note: a business object is also a function module in R/3) to deal with.
The control record has a fixed pre-defined structure, which is defined in the data
dictionary as EDIDC and can be viewed with SE11 in the R/3 data dictionary. The
header of our example will tell us, that the IDoc has been received from a sender
with the name PROCLNT100 and sent to the system with the name DEVCLNT100 .
It further tells us that the IDoc is to be interpreted according to the IDoc definition called MATMAS01 .
All records in the IDocs, which come after the control record are the IDoc data. They are all structured alike, with a segment information part and a data part which is 1000 characters in length, filling the rest of the line.
All records of an IDoc are structured the same way, regardless of their actual
content. They are records with a fixed length segment info part to the left, which is
followed by the segment data, which is always 1000 characters long.
You can view the definition of any IDoc data structure directly within R/3 with transaction WE30.
Regardless of the used IDoc type, all IDocs are stored in the same database tables
EDID4 for release 4.x and EDID3 for release 2.x and 3.x. Both release formats are
slightly different with respect to the lengths of some fields.
Depending on the R/3 release, the IDoc data records are formatted either according
the DDic structure EDID3 or EDID3. The difference between the two structures
reflects mainly the changes in the R/3 repository, which allow longer names starting
from release 4.x.
All IDoc data record have a segment info part and 1000 characters for data IDoc type definition can be edited with WE30 Data and segment info are stored in EDID4 .
All IDoc data records are exchanged in a fixed format, regardless of the segment type. The
segment’s true structure is stored in R/3’s repository as a DDic structure of the same name.
The segment info tells the IDoc processor how the current segment data is structured
and should be interpreted. The information, which is usually the only interest, is the name of the segment EDID4-SEGNAM.
The segment name corresponds to a data dictionary structure with the same name,
which has been created automatically when defining the IDoc segment definition
with transaction WE31 .
For most applications, the remaining information in the segment info can be ignored
as being redundant. Some older, non-SAP-compliant partners may require it. E.g.
the IDoc segment info will also store the unique segment number for systems, which
require numeric segment identification.
To have the segment made up for processing in an ABAP, it is usually wise to move
the segment data into a structure, which matches the segment definition.
When R/3 processes an IDoc via the standard inbound or outbound mechanism, the IDoc is stored in the tables. The control record goes to table EDIDC and the data goes to table EDID4.
All IDoc, whether sent or received are stored in the table EDID4. The corresponding
control file header goes into EDIDC.
There are standard programs that read and write the data to and from the IDoc base.
These programs and transaction are heavily dependent on the customising, where
rules are defined which tell how the IDocs are to be processed.
Of course, as IDocs are nothing more than structured ASCII data, you could always
process them directly with an ABAP. This is certainly the quick and dirty solution,
bypassing all the internal checks and processing mechanisms. We will not reinvent
the wheel here.
To do this customising setting, check with transaction WEDI and see the points,
dealing with ports, partner profiles, and all under IDoc development.
All inbound and outbound Documents are stored in EDID4 Avoid reinventing the
wheel Customising is done from the central menu WEDI and see the points,
dealing with ports, partner profiles, and all under IDoc development.
entity. It makes sense to see an IDoc as a plain and simple ASCII text file, even if it
might be transported via other means.
Any IDoc consists of two sections:
the control record
which is always the first line of the file and provides the administrative information.
the data record which contains the application dependent data, as in our example below the material master data.
We will discuss the exchange of the material master IDoc MATMAS in the
paragraphs that follow..
The definition of the IDoc structure MATMAS01 is deposited in the data dictionary
and can be viewed with WE30.
The very first record of an IDoc package is always a control record. The structure of this control record is the DDic structure EDIDC and describes the contents of the data contained in the package.
The control record carries all the administrative information of the IDoc, such as its origin, its destination and a categorical description of the contents and context of the attached IDoc data. This is very much like the envelope or cover sheet that
would accompany any paper document sent via postal mail.
For R/3 inbound processing, the control record is used by the standard IDoc
processing mechanism to determine the method for processing the IDoc. This
method is usually a function module but may be a business object as well. The
processing method can be fully customised.
Once the IDoc data is handed over to a processing function module, you will no
longer need the control record information. The function modules are aware of the
individual structure of the IDoc type and the meaning of the data. In other words:
for every context and syntax of an IDoc, you would write an individual function module or business object (note: a business object is also a function module in R/3) to deal with.
The control record has a fixed pre-defined structure, which is defined in the data
dictionary as EDIDC and can be viewed with SE11 in the R/3 data dictionary. The
header of our example will tell us, that the IDoc has been received from a sender
with the name PROCLNT100 and sent to the system with the name DEVCLNT100 .
It further tells us that the IDoc is to be interpreted according to the IDoc definition called MATMAS01 .
All records in the IDocs, which come after the control record are the IDoc data. They are all structured alike, with a segment information part and a data part which is 1000 characters in length, filling the rest of the line.
All records of an IDoc are structured the same way, regardless of their actual
content. They are records with a fixed length segment info part to the left, which is
followed by the segment data, which is always 1000 characters long.
You can view the definition of any IDoc data structure directly within R/3 with transaction WE30.
Regardless of the used IDoc type, all IDocs are stored in the same database tables
EDID4 for release 4.x and EDID3 for release 2.x and 3.x. Both release formats are
slightly different with respect to the lengths of some fields.
Depending on the R/3 release, the IDoc data records are formatted either according
the DDic structure EDID3 or EDID3. The difference between the two structures
reflects mainly the changes in the R/3 repository, which allow longer names starting
from release 4.x.
All IDoc data record have a segment info part and 1000 characters for data IDoc type definition can be edited with WE30 Data and segment info are stored in EDID4 .
All IDoc data records are exchanged in a fixed format, regardless of the segment type. The
segment’s true structure is stored in R/3’s repository as a DDic structure of the same name.
The segment info tells the IDoc processor how the current segment data is structured
and should be interpreted. The information, which is usually the only interest, is the name of the segment EDID4-SEGNAM.
The segment name corresponds to a data dictionary structure with the same name,
which has been created automatically when defining the IDoc segment definition
with transaction WE31 .
For most applications, the remaining information in the segment info can be ignored
as being redundant. Some older, non-SAP-compliant partners may require it. E.g.
the IDoc segment info will also store the unique segment number for systems, which
require numeric segment identification.
To have the segment made up for processing in an ABAP, it is usually wise to move
the segment data into a structure, which matches the segment definition.
When R/3 processes an IDoc via the standard inbound or outbound mechanism, the IDoc is stored in the tables. The control record goes to table EDIDC and the data goes to table EDID4.
All IDoc, whether sent or received are stored in the table EDID4. The corresponding
control file header goes into EDIDC.
There are standard programs that read and write the data to and from the IDoc base.
These programs and transaction are heavily dependent on the customising, where
rules are defined which tell how the IDocs are to be processed.
Of course, as IDocs are nothing more than structured ASCII data, you could always
process them directly with an ABAP. This is certainly the quick and dirty solution,
bypassing all the internal checks and processing mechanisms. We will not reinvent
the wheel here.
To do this customising setting, check with transaction WEDI and see the points,
dealing with ports, partner profiles, and all under IDoc development.
All inbound and outbound Documents are stored in EDID4 Avoid reinventing the
wheel Customising is done from the central menu WEDI and see the points,
dealing with ports, partner profiles, and all under IDoc development.
SAP ABAP IDOC PROCESSING
Creating and processing IDocs is primarily a mechanical task, which is certainly true for most interface programming. We will show a short example that packs SAP R/3 SAPscript standard text elements into IDocs and stores them.
Outbound IDocs from R/3 are usually created by a function module. This function
module is dynamically called by the IDoc engine. A sophisticated customising
defines the conditions and parameters to find the correct function module.
The interface parameters of the processing function need to be compatible with a
well-defined standard, because the function module will be called from within
another program.
IDoc inbound functions are function modules with a standard interface, which will
interpret the received IDoc data and prepare it for processing.
The received IDoc data is processed record by record and interpreted according to
the segment information provided with each record. The prepared data can then be
processed by an application, a function module, or a self-written program.
The example programs in the following chapters will show you how texts from the
text pool can be converted into an IDoc and processed by an inbound routine to be
stored into another system.
The following will give you the basics to understand the example:
SAP R/3 allows the creation of text elements, e.g. with transaction SO10. Each
standard text element has a control record which is stored in table STXH. The text
lines themselves are stored in a special cluster table. To retrieve the text from the
cluster, you will use the standard function module function READ_TEXT . We
will read such a text and pack it into an IDoc. That is what the following simple
function module does.
If there is no convenient routine to process data, the easiest way to hand over the
data to an application is to record a transaction with transaction SHDB and create a
simple processing function module from that recording.
Outbound routines are called by the triggering application, e.g. the RSNAST00
program.
Inbound processing is triggered by the central IDoc inbound handler, which is
usually the function module IDOC_INPUT . This function is usually activated by
the gatekeeper who receives the IDoc.
Outbound is triggered by the application.
Inbound is triggered by an external event.
The most difficult work when creating outbound IDocs is the retrieval of the application data which needs sending. Once the data is retrieved, it needs to be converted to IDoc format, only.
Each R/3 standard text element has a header record which is stored in table STXH.
The text lines themselves are stored in a special cluster table. To retrieve the text
from the cluster, you will use the standard function module function
READ_TEXT.
The program below will retrieve a text document from the text pool, convert the text
lines into IDoc format, and create the necessary control information.
The first step is reading the data from the application database by calling the
function module READ_TEXT.
Our next duty is to pack the data into the IDoc record. This means moving the
application data to the data part of the IDoc record structure EDIDD and filling the
corresponding segment information.
Finally, we have to provide a correctly filled control record for this IDoc. If the IDoc routine is used in a standard automated environment, it is usually sufficient to fill the field EDIDC-IDOCTP with the IDoc type, EDIDC-MESTYP with the context
message type and the receiver name. The remaining fields are automatically filled
by the standard processing routines if applicable.
Inbound processing is basically the reverse process of an outbound.. The received IDoc has to be unpacked, interpreted and transferred to an application for further processing.
The received IDoc data is processed record by record and data is sorted out according to the segment type.
When the IDoc is unpacked data is passed to the application.
Finally the processing routine needs to pass a status record to the IDoc processor.
This status indicates successful or unsuccessful processing and will be added as a
log entry to the table EDIDS.
The status value '51' indicates a general error during application processing and the
status '53' indicates everything is OK.
Outbound IDocs from R/3 are usually created by a function module. This function
module is dynamically called by the IDoc engine. A sophisticated customising
defines the conditions and parameters to find the correct function module.
The interface parameters of the processing function need to be compatible with a
well-defined standard, because the function module will be called from within
another program.
IDoc inbound functions are function modules with a standard interface, which will
interpret the received IDoc data and prepare it for processing.
The received IDoc data is processed record by record and interpreted according to
the segment information provided with each record. The prepared data can then be
processed by an application, a function module, or a self-written program.
The example programs in the following chapters will show you how texts from the
text pool can be converted into an IDoc and processed by an inbound routine to be
stored into another system.
The following will give you the basics to understand the example:
SAP R/3 allows the creation of text elements, e.g. with transaction SO10. Each
standard text element has a control record which is stored in table STXH. The text
lines themselves are stored in a special cluster table. To retrieve the text from the
cluster, you will use the standard function module function READ_TEXT . We
will read such a text and pack it into an IDoc. That is what the following simple
function module does.
If there is no convenient routine to process data, the easiest way to hand over the
data to an application is to record a transaction with transaction SHDB and create a
simple processing function module from that recording.
Outbound routines are called by the triggering application, e.g. the RSNAST00
program.
Inbound processing is triggered by the central IDoc inbound handler, which is
usually the function module IDOC_INPUT . This function is usually activated by
the gatekeeper who receives the IDoc.
Outbound is triggered by the application.
Inbound is triggered by an external event.
The most difficult work when creating outbound IDocs is the retrieval of the application data which needs sending. Once the data is retrieved, it needs to be converted to IDoc format, only.
Each R/3 standard text element has a header record which is stored in table STXH.
The text lines themselves are stored in a special cluster table. To retrieve the text
from the cluster, you will use the standard function module function
READ_TEXT.
The program below will retrieve a text document from the text pool, convert the text
lines into IDoc format, and create the necessary control information.
The first step is reading the data from the application database by calling the
function module READ_TEXT.
Our next duty is to pack the data into the IDoc record. This means moving the
application data to the data part of the IDoc record structure EDIDD and filling the
corresponding segment information.
Finally, we have to provide a correctly filled control record for this IDoc. If the IDoc routine is used in a standard automated environment, it is usually sufficient to fill the field EDIDC-IDOCTP with the IDoc type, EDIDC-MESTYP with the context
message type and the receiver name. The remaining fields are automatically filled
by the standard processing routines if applicable.
Inbound processing is basically the reverse process of an outbound.. The received IDoc has to be unpacked, interpreted and transferred to an application for further processing.
The received IDoc data is processed record by record and data is sorted out according to the segment type.
When the IDoc is unpacked data is passed to the application.
Finally the processing routine needs to pass a status record to the IDoc processor.
This status indicates successful or unsuccessful processing and will be added as a
log entry to the table EDIDS.
The status value '51' indicates a general error during application processing and the
status '53' indicates everything is OK.
SAP ABAP IDOC'S BASIC TOOLS I
There are several common expressions and methods that you need to know, when dealing
with IDoc.
The message type defines the semantic context of an IDoc. The message type tells
the processing routines, how the message has to be interpreted.
The same IDoc data can be sent with different message types. E.g. The same IDoc
structure which is used for a purchase order can also be used for transmitting a sales order. Imagine the situation that you receive a sales order from your clients and in addition you receive copies of sales orders sent by an subsidiary of your company.
An IDoc type defines the syntax of the IDoc data. It tells which segments are found
in an Idoc and what fields the segments are made of.
The processing code is a logical name that determines the processing routine. This
points usually to a function module, but the processing routine can also be a
workflow or an event.
The use of a logical processing code makes it easy to modify the processing routine
for a series of partner profiles at once.
Every sender-receiver relationship needs a profile defined. This one determines
• the processing code
• the processing times and conditions
• and in the case of outbound IDocs
• the media port used to send the IDoc and
• the triggers used to send the IDoc
The IDoc partners are classified in logical groups. Up to release 4.5 there were the
following standard partner types defined: LS, KU, LI.
The logical system is meant to be a different computer and was primarily introduced
for use with the ALE functionality. You would use a partner type of LS, when
linking with a different computer system, e.g. a legacy or subsystem.
The partner type customer is used in classical EDI transmission to designate a
partner, that requires a service from your company or is in the role of a debtor with
respect to your company, e.g. the payer, sold-to-party, ship-to-party.
The partner type supplier is used in classical EDI transmission to designate a
partner, that delivers a service to your company. This is typically the supplier in a
purchase order. In SD orders you also find LI type partners, e.g. the shipping agent.
Message Type – How to Know What the Data Means
Data exchanged by an IDoc via EDI is known as message. Messages of the same kind belong to the same message type.
The message type defines the semantic context of an IDoc. The message type tells
the receiverhow the message has to be interpreted.
The term message is commonly used in communication, be it EDI or
telecommunication. Any stream of data sent to a receiver with well-defined
information in itis known as a message. EDIFACT, ANSI/X.12, XML and others
use message the same way.
Unfortunately, the term message is used in many contexts other than EDI as well.
Even R/3 uses the word message for the internal communication between
applications. While this is totally OK from the abstract point of view of data
modelling, it may sometimes cause confusion if it is unclear whether we are
referring to IDoc messages or internal messages.
The specification of the message type along with the sent IDoc package is especially
important when the physical IDoc type (the data structure of the IDoc file) is used
for different purposes.
A classical ambiguity arises in communication with customs via EDI. They usually
set up a universal file format for an arbitrary kind of declaration, e.g. Intrastat,
Extrastat, Export declarations, monthly reports etc. Depending on the message type,
only applicable fields are filled with valid data. The message type tells the receiver which fields are of interest at all.
Partner Profiles – How to Know the Format of the Partner
Different partners may speak different languages. While the information remains the same, different receivers may require completely different file formats and communication protocols.
This information is stored in a partner profile.
In a partner profile you will specify the names of the partners which are allowed to
exchange IDocs to your system. For each partner you have to list the message types
that the partner may send.
For any such message type, the profile tells the IDoc type, which the partner expects
for that kind of message.
For outbound processing, the partner profile also sets the media to transport the data to its receiver, e.g.
• an operating system file
• automated FTP
• XML or EDIFACT transmission via a broker/converter
• internet
• direct remote function call
The means of transport depends on the receiving partner, the IDoc type and message
type (context).
Therefore, you may choose to send the same data as a file to your vendor and via
FTP to your remote plant.
Also you may decide to exchange purchase data with a vendor via FTP but send
payment notes to the same vendor in a file.
For inbound processing, the partner profile customizsng will also determine a
processing code, which can handle the received data.
IDoc Type – The Structure of the IDoc File
The IDoc type is the name of the data structure used to describe the file format of a specific IDoc.
An IDoc is a segmented data file. It has typically several segments. The segments
are usually structured into fields; however, different segments use different fields.
The Idoc type is defined with transaction WE30, the respective segments are defined
with transaction WE31.
Processing Codes
The processing code is a pointer to an algorithm to process an IDoc. It is used to allow more flexibility in assigning the processing function to an IDoc message.
The processing code is a logical name for the algorithm used to process the IDoc.
The processing code points itself to a method or function, which is capable of
processing the IDoc data.
A processing code can point to an SAP predefined or a self-written business object
or function module as long as they comply with certain interface standards.
The processing codes allow you to easily change the processing algorithm. Because
the process code can be used for more than one partner profile, the algorithm can be
easily changed for every concerned IDoc.
The IDoc engine will call a function module or a business object which is expected
to perform the application processing for the received IDoc data. The function
module must provide exactly the interface parameters which are needed to call it
from the IDoc engine.
In addition to the writing of the processing function modules, IDoc development requires the
definition of the segment structures and a series of customising settings to control the flow of the IDoc engine.
In Summary
Customise basic installation parameters
Define segment structures
Define message types, processing codes
Segments define the structure of the records in an IDoc. They are defined with transaction WE31.
Check first, whether the client you are working with already has a logical system
name assigned.
The logical system name is stored in table T000 as T000-LOGSYS. This is the table
of installed clients.
If there is no name defined, you need to create a logical system name . This means
simply adding a line to table TBDLS. You can edit the table directly or access the
table from transaction SALE.
The recommended naming convention is
sysid + "CLNT" + client
If your system is DEV and client is 100, then the logical system name should be:
DEVCLNT100.
System PRO with client 123 would be PROCLNT123 etc.
The logical system also needs to be defined as a target within the R/3 network.
Those definitions are done with transaction SM59 and are usually part of the work
of the R/3 basis team.

with IDoc.
The message type defines the semantic context of an IDoc. The message type tells
the processing routines, how the message has to be interpreted.
The same IDoc data can be sent with different message types. E.g. The same IDoc
structure which is used for a purchase order can also be used for transmitting a sales order. Imagine the situation that you receive a sales order from your clients and in addition you receive copies of sales orders sent by an subsidiary of your company.
An IDoc type defines the syntax of the IDoc data. It tells which segments are found
in an Idoc and what fields the segments are made of.
The processing code is a logical name that determines the processing routine. This
points usually to a function module, but the processing routine can also be a
workflow or an event.
The use of a logical processing code makes it easy to modify the processing routine
for a series of partner profiles at once.
Every sender-receiver relationship needs a profile defined. This one determines
• the processing code
• the processing times and conditions
• and in the case of outbound IDocs
• the media port used to send the IDoc and
• the triggers used to send the IDoc
The IDoc partners are classified in logical groups. Up to release 4.5 there were the
following standard partner types defined: LS, KU, LI.
The logical system is meant to be a different computer and was primarily introduced
for use with the ALE functionality. You would use a partner type of LS, when
linking with a different computer system, e.g. a legacy or subsystem.
The partner type customer is used in classical EDI transmission to designate a
partner, that requires a service from your company or is in the role of a debtor with
respect to your company, e.g. the payer, sold-to-party, ship-to-party.
The partner type supplier is used in classical EDI transmission to designate a
partner, that delivers a service to your company. This is typically the supplier in a
purchase order. In SD orders you also find LI type partners, e.g. the shipping agent.
Message Type – How to Know What the Data Means
Data exchanged by an IDoc via EDI is known as message. Messages of the same kind belong to the same message type.
The message type defines the semantic context of an IDoc. The message type tells
the receiverhow the message has to be interpreted.
The term message is commonly used in communication, be it EDI or
telecommunication. Any stream of data sent to a receiver with well-defined
information in itis known as a message. EDIFACT, ANSI/X.12, XML and others
use message the same way.
Unfortunately, the term message is used in many contexts other than EDI as well.
Even R/3 uses the word message for the internal communication between
applications. While this is totally OK from the abstract point of view of data
modelling, it may sometimes cause confusion if it is unclear whether we are
referring to IDoc messages or internal messages.
The specification of the message type along with the sent IDoc package is especially
important when the physical IDoc type (the data structure of the IDoc file) is used
for different purposes.
A classical ambiguity arises in communication with customs via EDI. They usually
set up a universal file format for an arbitrary kind of declaration, e.g. Intrastat,
Extrastat, Export declarations, monthly reports etc. Depending on the message type,
only applicable fields are filled with valid data. The message type tells the receiver which fields are of interest at all.
Partner Profiles – How to Know the Format of the Partner
Different partners may speak different languages. While the information remains the same, different receivers may require completely different file formats and communication protocols.
This information is stored in a partner profile.
In a partner profile you will specify the names of the partners which are allowed to
exchange IDocs to your system. For each partner you have to list the message types
that the partner may send.
For any such message type, the profile tells the IDoc type, which the partner expects
for that kind of message.
For outbound processing, the partner profile also sets the media to transport the data to its receiver, e.g.
• an operating system file
• automated FTP
• XML or EDIFACT transmission via a broker/converter
• internet
• direct remote function call
The means of transport depends on the receiving partner, the IDoc type and message
type (context).
Therefore, you may choose to send the same data as a file to your vendor and via
FTP to your remote plant.
Also you may decide to exchange purchase data with a vendor via FTP but send
payment notes to the same vendor in a file.
For inbound processing, the partner profile customizsng will also determine a
processing code, which can handle the received data.
IDoc Type – The Structure of the IDoc File
The IDoc type is the name of the data structure used to describe the file format of a specific IDoc.
An IDoc is a segmented data file. It has typically several segments. The segments
are usually structured into fields; however, different segments use different fields.
The Idoc type is defined with transaction WE30, the respective segments are defined
with transaction WE31.
Processing Codes
The processing code is a pointer to an algorithm to process an IDoc. It is used to allow more flexibility in assigning the processing function to an IDoc message.
The processing code is a logical name for the algorithm used to process the IDoc.
The processing code points itself to a method or function, which is capable of
processing the IDoc data.
A processing code can point to an SAP predefined or a self-written business object
or function module as long as they comply with certain interface standards.
The processing codes allow you to easily change the processing algorithm. Because
the process code can be used for more than one partner profile, the algorithm can be
easily changed for every concerned IDoc.
The IDoc engine will call a function module or a business object which is expected
to perform the application processing for the received IDoc data. The function
module must provide exactly the interface parameters which are needed to call it
from the IDoc engine.
In addition to the writing of the processing function modules, IDoc development requires the
definition of the segment structures and a series of customising settings to control the flow of the IDoc engine.
In Summary
Customise basic installation parameters
Define segment structures
Define message types, processing codes
Segments define the structure of the records in an IDoc. They are defined with transaction WE31.
Check first, whether the client you are working with already has a logical system
name assigned.
The logical system name is stored in table T000 as T000-LOGSYS. This is the table
of installed clients.
If there is no name defined, you need to create a logical system name . This means
simply adding a line to table TBDLS. You can edit the table directly or access the
table from transaction SALE.
The recommended naming convention is
sysid + "CLNT" + client
If your system is DEV and client is 100, then the logical system name should be:
DEVCLNT100.
System PRO with client 123 would be PROCLNT123 etc.
The logical system also needs to be defined as a target within the R/3 network.
Those definitions are done with transaction SM59 and are usually part of the work
of the R/3 basis team.
SAP ABAP IDOC'S BASIC TOOLS II
Creating an IDoc Segment WE31:
The segment defines the structure of the records in an IDoc. They are defined with transaction WE31.
We will define a structure to send a text from the text database.
Transaction WE31 calls the IDoc segment editor. The editor defines the fields of a
single segment structure. The thus defined IDoc segment is then created as a data
dictionary structure. You can view the created structure with SE11 and use it in an
ABAP as any TABLES declaration.
To demonstrate the use of the IDoc segment editor we will set up an example, which
allows you to send a single text from the text pool (tables STXH and STXL) as an
IDoc. These are the texts that you can see with SO10 or edit from within many
applications.
We will show the steps to define an IDoc segment YAXX_THEAD with the DDic
structure of THEAD.
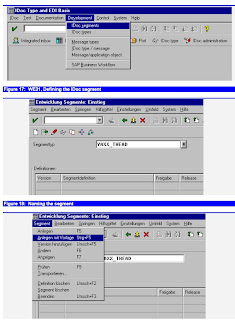
To facilitate our work, we will use the "copy-from-template-tool", which reads the
definition of a DDIC structure and inserts the field and the matching definitions as
rows in the IDoc editor. You could, of course, define the structure completely
manually, but using the template makes it easier.
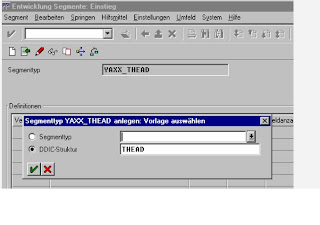
The tool in release 4.0b lets you use both DDIC structures or another IDoc segment
definition as a template.
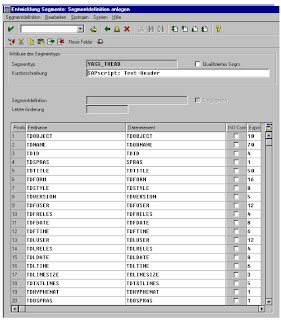
The thus created structure can be edited any time. When saving, it will create a data
dictionary structure based on the definition in WE31. The DDIC structure will retain
the same name. You can view the structure as a table definition with SE11 and use it
in an ABAP the same way.
Defining the Message Type (EDMSG)
The message type defines the context under which an IDoc is transferred to its destination. It allows for using the same IDoc file format for several different applications.
Imagine the situation of sending a purchase order to a supplier. When the IDoc with
the purchase order reaches the supplier, it will be interpreted as a sales order
received from a customer, namely you.
Simultaneously you want to send the IDoc data to the supplier's warehouse to inform
it that a purchase order has been issued and is on the way.
Both IDoc receivers will receive the same IDoc format; however, the IDoc will be
tagged with a different message type. While the IDoc to the supplier will be flagged
as a purchase order (in SAP R/3 standard: message type = ORDERS), the same IDoc
sent to the warehouse should be flagged differently, so that the warehouse can
recognize the order as a mere informational copy and process it differently than a
true purchase order.
The message type together with the IDoc type determine the processing function.
The message types are stored in table EDMSG.
Defining the message type can be done from the transaction WEDI
EDMSG: Defining the message type (1)
The entry is only a base entry which tells the system that the message type is
allowed. Other transactions will use that table as a check table to validate the entry.
IT is as shown .
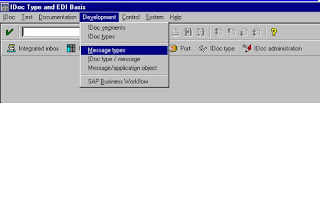
EDMSG: Defining the message type (1):
The entry is only a base entry which tells the system that the message type is
allowed. Other transactions will use that table as a check table to validate the entry.

The segment defines the structure of the records in an IDoc. They are defined with transaction WE31.
We will define a structure to send a text from the text database.
Transaction WE31 calls the IDoc segment editor. The editor defines the fields of a
single segment structure. The thus defined IDoc segment is then created as a data
dictionary structure. You can view the created structure with SE11 and use it in an
ABAP as any TABLES declaration.
To demonstrate the use of the IDoc segment editor we will set up an example, which
allows you to send a single text from the text pool (tables STXH and STXL) as an
IDoc. These are the texts that you can see with SO10 or edit from within many
applications.
We will show the steps to define an IDoc segment YAXX_THEAD with the DDic
structure of THEAD.
To facilitate our work, we will use the "copy-from-template-tool", which reads the
definition of a DDIC structure and inserts the field and the matching definitions as
rows in the IDoc editor. You could, of course, define the structure completely
manually, but using the template makes it easier.
The tool in release 4.0b lets you use both DDIC structures or another IDoc segment
definition as a template.
The thus created structure can be edited any time. When saving, it will create a data
dictionary structure based on the definition in WE31. The DDIC structure will retain
the same name. You can view the structure as a table definition with SE11 and use it
in an ABAP the same way.
Defining the Message Type (EDMSG)
The message type defines the context under which an IDoc is transferred to its destination. It allows for using the same IDoc file format for several different applications.
Imagine the situation of sending a purchase order to a supplier. When the IDoc with
the purchase order reaches the supplier, it will be interpreted as a sales order
received from a customer, namely you.
Simultaneously you want to send the IDoc data to the supplier's warehouse to inform
it that a purchase order has been issued and is on the way.
Both IDoc receivers will receive the same IDoc format; however, the IDoc will be
tagged with a different message type. While the IDoc to the supplier will be flagged
as a purchase order (in SAP R/3 standard: message type = ORDERS), the same IDoc
sent to the warehouse should be flagged differently, so that the warehouse can
recognize the order as a mere informational copy and process it differently than a
true purchase order.
The message type together with the IDoc type determine the processing function.
The message types are stored in table EDMSG.
Defining the message type can be done from the transaction WEDI
EDMSG: Defining the message type (1)
The entry is only a base entry which tells the system that the message type is
allowed. Other transactions will use that table as a check table to validate the entry.
IT is as shown .
EDMSG: Defining the message type (1):
The entry is only a base entry which tells the system that the message type is
allowed. Other transactions will use that table as a check table to validate the entry.
SAP ABAP IDOC'S INBOUND BASIC TOOLS III
The declaration of valid combinations is done to allow validation, if the system can
handle a certain combination.
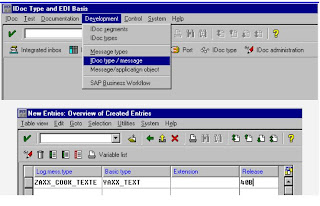
The combination of message type and IDoc type determine the processing algorithm. This is
usually a function module with a well defined interface or a SAP business object and is set up
in table EDIFCT.
The entry made here points to a function module which will be called when the IDoc
is to be processed.
The entries for message code and message function are usually left blank. They can
be used to derive sub types of messages together with the partner profile used.
Figure 25: Assign a handler function to a message/message type
The definition for inbound and outbound IDocs is analogous. Of course, the function
module will be different.
R/3 uses the method of logical process codes to detach the IDoc processing and the
processing function module. They assign a logical name to the function instead of specifying the physical function name.
The IDoc functions are often used for a series of message type/IDoc type
combination. It is necessary to replace the processing function by a different one.
E.g. when you make a copy of a standard function to avoid modifying the standard.
The combination message type/IDoc will determine the logical processing code,
which itself points to a function. If the function changes, only the definition of the processing codes will be changed and the new function will be immediately
effective for all IDocs associated with the process code.
For inbound processing codes you have to specify the method to use for the
determination of the inbound function.
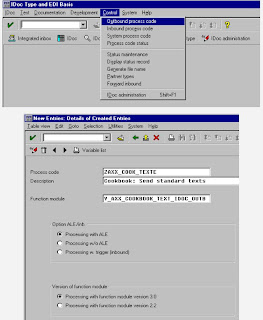
This is the option you would usually choose. It allows processing via the ALE
scenarios.
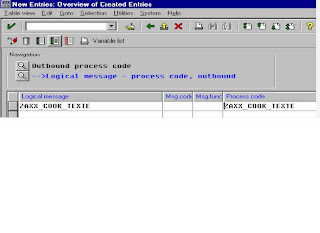
After defining the processing code you have to assign it to one or several logical
message types. This declaration is used to validate, if a message can be handled by
the receiving system.
The inbound processing code is assigned analogously. The processing code is a pointer to a function module which can handle the inbound request for the specified IDoc and message type.
The definition of the processing code is identifying the handler routine and assigning a serious of processing options.
You need to click "Processing with ALE", if your function can be used via the ALE
engine. This is the option you would usually choose. It allows processing via the
ALE scenarios.
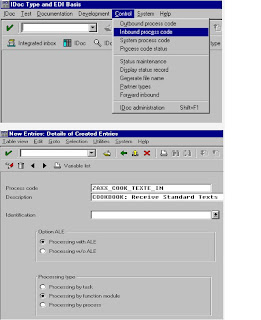
Associate a function module with a process code
For inbound processing you need to indicate whether the function will be capable of
dialog processing. This is meant for those functions which process the inbound data
via call transaction. Those functions can be replayed in visible batch input mode to
check why the processing might have failed.
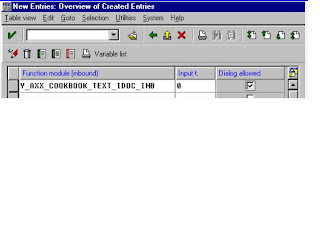

handle a certain combination.
The combination of message type and IDoc type determine the processing algorithm. This is
usually a function module with a well defined interface or a SAP business object and is set up
in table EDIFCT.
The entry made here points to a function module which will be called when the IDoc
is to be processed.
The entries for message code and message function are usually left blank. They can
be used to derive sub types of messages together with the partner profile used.
Figure 25: Assign a handler function to a message/message type
The definition for inbound and outbound IDocs is analogous. Of course, the function
module will be different.
R/3 uses the method of logical process codes to detach the IDoc processing and the
processing function module. They assign a logical name to the function instead of specifying the physical function name.
The IDoc functions are often used for a series of message type/IDoc type
combination. It is necessary to replace the processing function by a different one.
E.g. when you make a copy of a standard function to avoid modifying the standard.
The combination message type/IDoc will determine the logical processing code,
which itself points to a function. If the function changes, only the definition of the processing codes will be changed and the new function will be immediately
effective for all IDocs associated with the process code.
For inbound processing codes you have to specify the method to use for the
determination of the inbound function.
This is the option you would usually choose. It allows processing via the ALE
scenarios.
After defining the processing code you have to assign it to one or several logical
message types. This declaration is used to validate, if a message can be handled by
the receiving system.
The inbound processing code is assigned analogously. The processing code is a pointer to a function module which can handle the inbound request for the specified IDoc and message type.
The definition of the processing code is identifying the handler routine and assigning a serious of processing options.
You need to click "Processing with ALE", if your function can be used via the ALE
engine. This is the option you would usually choose. It allows processing via the
ALE scenarios.
Associate a function module with a process code
For inbound processing you need to indicate whether the function will be capable of
dialog processing. This is meant for those functions which process the inbound data
via call transaction. Those functions can be replayed in visible batch input mode to
check why the processing might have failed.
SAP IDOC OUT BOUND TRIGGERS II
IDocs should be sent out at certain events. Therefore you have to define a trigger. A lot of consideration is required to determine the correct moment when to send out the IDoc. The IDoc can be triggered at a certain time or when an event is raised. R/3 uses several completely different methods to determine the trigger point.
There are messages to tell the system that there is an IDoc waiting for dispatching, there are log files which may be evaluated to see if IDocs are due to send and there can be a workflow chain triggered, which includes the sending of the IDoc.
The simplest way to create IDocs, is to write an ABAP. The individual ABAP can either be a triggering ABAP which runs at certain events, e.g. every night, or it can be an ABAP which does the complete IDoc creation from scratch.
A triggering ABAP would simply try to determine which IDocs need sending and
call the appropriate IDoc creation routines.
You may also imagine the ABAP to do all the job. As this is mostly reinventing the
wheel, it is not really recommended and should be reserved to situation, where the
other solution do not provide an appropriate mean.
You can use the R/3 message concept to trigger IDocs the same way as you trigger SAPscript printing.
One of the key tables in R/3 is the table NAST. This table records reminders written
by applications. Those reminders are called messages.
Every time when an applications sees the necessity to pass information to a third
party. a message is written to NAST. A message handler will eventually check the
entries in the table and cause an appropriate action.
The concept of NAST messages has originally been designed for triggering
SAPscript printing. The very same mechanism is used for IDocs, where the IDoc
processor replaces the print task, as an IDoc is only the paperless form of a printed
document.
The messages are usually be created using the condition technique, a mechanism
available to all major R/3 applications.
The conditions are set up the same way for any output media. So you may define a
condition for printing a document and then just change the output media from
printer to IDoc/EDI or ALE.
Creating NAST messages is a standard functionality in most of the SAP core
applications. Those applications - e.g. VA01, ME21 - perform calls to the central
function module MESSAGING of group V61B. The function module uses
customizing entries, mainly those of the tables T681* to T685*.
A NAST output message is stored as a single record in the table NAST. The record
stores all information that is necessary to create an IDoc. This includes mainly an
object key to identify the processed object and application to the message handler
and the sender and receiver information.
Creating NAST messages is a standard functionality in most of the SAP core
applications. Those applications - e.g. VA01, ME21 - perform calls to the central
function module MESSAGING of group V61B. The function module uses
customizing entries, mainly those of the tables T681* to T685*.
A NAST output message is stored as a single record in the table NAST. The record
stores all information that is necessary to create an IDoc. This includes mainly an
object key to identify the processed object and application to the message handler
and the sender and receiver information.
There are messages to tell the system that there is an IDoc waiting for dispatching, there are log files which may be evaluated to see if IDocs are due to send and there can be a workflow chain triggered, which includes the sending of the IDoc.
The simplest way to create IDocs, is to write an ABAP. The individual ABAP can either be a triggering ABAP which runs at certain events, e.g. every night, or it can be an ABAP which does the complete IDoc creation from scratch.
A triggering ABAP would simply try to determine which IDocs need sending and
call the appropriate IDoc creation routines.
You may also imagine the ABAP to do all the job. As this is mostly reinventing the
wheel, it is not really recommended and should be reserved to situation, where the
other solution do not provide an appropriate mean.
You can use the R/3 message concept to trigger IDocs the same way as you trigger SAPscript printing.
One of the key tables in R/3 is the table NAST. This table records reminders written
by applications. Those reminders are called messages.
Every time when an applications sees the necessity to pass information to a third
party. a message is written to NAST. A message handler will eventually check the
entries in the table and cause an appropriate action.
The concept of NAST messages has originally been designed for triggering
SAPscript printing. The very same mechanism is used for IDocs, where the IDoc
processor replaces the print task, as an IDoc is only the paperless form of a printed
document.
The messages are usually be created using the condition technique, a mechanism
available to all major R/3 applications.
The conditions are set up the same way for any output media. So you may define a
condition for printing a document and then just change the output media from
printer to IDoc/EDI or ALE.
Creating NAST messages is a standard functionality in most of the SAP core
applications. Those applications - e.g. VA01, ME21 - perform calls to the central
function module MESSAGING of group V61B. The function module uses
customizing entries, mainly those of the tables T681* to T685*.
A NAST output message is stored as a single record in the table NAST. The record
stores all information that is necessary to create an IDoc. This includes mainly an
object key to identify the processed object and application to the message handler
and the sender and receiver information.
Creating NAST messages is a standard functionality in most of the SAP core
applications. Those applications - e.g. VA01, ME21 - perform calls to the central
function module MESSAGING of group V61B. The function module uses
customizing entries, mainly those of the tables T681* to T685*.
A NAST output message is stored as a single record in the table NAST. The record
stores all information that is necessary to create an IDoc. This includes mainly an
object key to identify the processed object and application to the message handler
and the sender and receiver information.
SAP IDOCS OUTBOUND TRIGGER II
The messages are typically processed by
FORM ENTRY in PROGRAM RSNAST00.
If we are dealing with printing or faxing and
FORM EDI_PROCESSING in PROGRAM RSNASTED.
If we are dealing with IDocs
FORM ALE_PROCESSING in PROGRAM RSNASTED.
If we are dealing with ALE.
The following piece of code does principally the same thing as RSNAST00 does and
makes full use of all customizing settings for message handling.
TABLES: NAST.
SELECT * FROM NAST ...
PERFORM einzelnachricht IN PROGRAM RSNAST00
The processing routine for the respective media and message is customized in the
table TNAPR. This table records the name of a FORM routine, which processes the
message for the chosen media and the name of an ABAP where this FORM is found.
The ABAP RSNAST00 is the standard ABAP, which is used to collect unprocessed NAST
message and to execute the assigned action.
RSNAST00 can be executed as a collector batch run, that eventually looks for
unprocessed IDocs. The usual way of doing that is to define a batch-run job with
transaction SM37. This job has to be set for periodic processing and start a program
that triggers the IDoc re-sending.
Cave! RSNAST00 will only look for IDocs which are set to NAST-VSZTP = '1' or '2'
(Time of processing). VSZPT = '3' or '4' is ignored by RSNAST00.
Start RSNAST00 in the foreground first and find the parameters that match your
required selection criteria. Save them as a VARIANT and then define the periodic
batch job using the variant.
If RSNAST00 does not meet 100% your needs you can create an own program
similar to RSNAST00. The only requirement for this program are two steps:
* Read the NAST entry to process into structure NAST
tables nast.
data: subrc like sy-subrc.....
select from NAST where .......
* then call FORM einzelnachricht(rsnast00) to process the record
PERFORM einzelnachricht(rsnast00) USING subrc.
FORM ENTRY in PROGRAM RSNAST00.
If we are dealing with printing or faxing and
FORM EDI_PROCESSING in PROGRAM RSNASTED.
If we are dealing with IDocs
FORM ALE_PROCESSING in PROGRAM RSNASTED.
If we are dealing with ALE.
The following piece of code does principally the same thing as RSNAST00 does and
makes full use of all customizing settings for message handling.
TABLES: NAST.
SELECT * FROM NAST ...
PERFORM einzelnachricht IN PROGRAM RSNAST00
The processing routine for the respective media and message is customized in the
table TNAPR. This table records the name of a FORM routine, which processes the
message for the chosen media and the name of an ABAP where this FORM is found.
The ABAP RSNAST00 is the standard ABAP, which is used to collect unprocessed NAST
message and to execute the assigned action.
RSNAST00 can be executed as a collector batch run, that eventually looks for
unprocessed IDocs. The usual way of doing that is to define a batch-run job with
transaction SM37. This job has to be set for periodic processing and start a program
that triggers the IDoc re-sending.
Cave! RSNAST00 will only look for IDocs which are set to NAST-VSZTP = '1' or '2'
(Time of processing). VSZPT = '3' or '4' is ignored by RSNAST00.
Start RSNAST00 in the foreground first and find the parameters that match your
required selection criteria. Save them as a VARIANT and then define the periodic
batch job using the variant.
If RSNAST00 does not meet 100% your needs you can create an own program
similar to RSNAST00. The only requirement for this program are two steps:
* Read the NAST entry to process into structure NAST
tables nast.
data: subrc like sy-subrc.....
select from NAST where .......
* then call FORM einzelnachricht(rsnast00) to process the record
PERFORM einzelnachricht(rsnast00) USING subrc.
SAP IDOC'S OUTBOUND TRIGGER III
Sending IDocs Via RSNASTED
Standard R/3 provides you with powerful routines, to trigger, prepare and send out IDocs in a controlled way. There are only a few rare cases, where you do not want to send IDocs the standard way.
The ABAP RSNAST00 is the standard routine to send IDocs from entries in the message control. This program can be called directly, from a batch routine with variant or you can call the FORM einzelnachricht_screen(RSNAST00) from any other program, while having the structure NAST correctly filled with all necessary information.
If there is an entry in table NAST, RSNAST00 looks up the associated processing
routine in table TNAPR. If it is to send an IDoc with standard means, this will
usually be the routine RSNASTED(EDI_PROCESSING) or RSNASTED(ALE_PROCESSING) in the case of ALE distribution.
RSNASTED itself determines the associated IDoc outbound function module,
executes it to fill the EDIDx tables and passes the prepared IDoc to the port.
You can call the standard processing routines from any ABAP, by executing the
following call to the routine. You only have to make sure that the structure NAST is
declared with the tables statement in the calling routine and that you fill at least the key part and the routine (TNAPR) information before.
TABLES NAST.
NAST-MANDT = SY-MANDT.
NAST-KSCHL = 'ZEDIK'.
NAST-KAPPL = 'V1'.
NAST-OBJKY = '0012345678'.
NAST-PARNR = 'D012345678'.
PERFORM einzelnachricht_screen(RSNAST00).
Calling einzelnachricht_screen determines how the message is processed.
If you want to force the IDoc-processing you can call it directly:
TNAPR-PROGN = ''.
TNAPR-ROUTN = 'ENTRY'.
PERFORM edi_processing(RSNASTED).
Standard R/3 provides you with powerful routines, to trigger, prepare and send out IDocs in a controlled way. There are only a few rare cases, where you do not want to send IDocs the standard way.
The ABAP RSNAST00 is the standard routine to send IDocs from entries in the message control. This program can be called directly, from a batch routine with variant or you can call the FORM einzelnachricht_screen(RSNAST00) from any other program, while having the structure NAST correctly filled with all necessary information.
If there is an entry in table NAST, RSNAST00 looks up the associated processing
routine in table TNAPR. If it is to send an IDoc with standard means, this will
usually be the routine RSNASTED(EDI_PROCESSING) or RSNASTED(ALE_PROCESSING) in the case of ALE distribution.
RSNASTED itself determines the associated IDoc outbound function module,
executes it to fill the EDIDx tables and passes the prepared IDoc to the port.
You can call the standard processing routines from any ABAP, by executing the
following call to the routine. You only have to make sure that the structure NAST is
declared with the tables statement in the calling routine and that you fill at least the key part and the routine (TNAPR) information before.
TABLES NAST.
NAST-MANDT = SY-MANDT.
NAST-KSCHL = 'ZEDIK'.
NAST-KAPPL = 'V1'.
NAST-OBJKY = '0012345678'.
NAST-PARNR = 'D012345678'.
PERFORM einzelnachricht_screen(RSNAST00).
Calling einzelnachricht_screen determines how the message is processed.
If you want to force the IDoc-processing you can call it directly:
TNAPR-PROGN = ''.
TNAPR-ROUTN = 'ENTRY'.
PERFORM edi_processing(RSNASTED).
SAP Work flow based outbound Idoc's
Unfortunately, there are application that do not create messages. This is especially true for master data applications. However, most applications fire a workflow event during update,which can easily be used to trigger the IDoc distribution.
Many SAP R/3 applications issue a call to the function SWE_EVENT_CREATE
during update. This function module ignites a simple workflow event.
Technically a workflow event is a timed call to a function module, which takes the
issuing event as the key to process a subsequent action.
If an application writes regular change documents (ger.: Änderungsbelege) to the
database, it will issue automatically a workflow event. This event is triggered from
within the function CHANGEDOCUMENT_CLOSE.
The change document workflow event is always triggered, independent of the case whether a change document is actually written.
In order to make use of the workflow for IDoc processing, you do not have to go
through the cumbersome workflow design procedure as it is described in the
workflow documentation. For the mentioned purpose, you can register the workflow
handler from the menu, which says Event Coupling from the BALD transaction.
Triggering the IDoc from a workflow event has a disadvantage: if the IDoc has to be
repeated for some reason, the event cannot be repeated easily. This is due to the
nature of a workflow event, which is triggered usually from a precedent action.
Therefore you have to find an own way how to make sure that the IDoc is actually
generated, even in the case of an error. Practically this is not a very big problem for IDocs. In most cases the creation of the IDoc will always take place. If there is a problem, then the IDoc would be stored in the IDoc base with a respective status. It will shown in transaction WE05 and can be resend from there.
Workflow Event From Change Document:
Most application fire a workflow event from the update routine by calling the
function
FUNCTION swe_event_create
You can check if an application fires events by activating the event log from
transaction SWLD. Calling and saving a transaction will write the event’s name and
circumstances into the log file.
If an application does not fire workflow events directly, there is still another chance that a workflow may be used without touching the R/3 original programs.
Every application that writes change documents triggers a workflow event from
within the function module CHANGEDOCUMENT_CLOSE, which is called form the
update processing upon writing the change document. This will call the workflow
processor.
FUNCTION swe_event_create_changedocument:
Both workflow types are not compatible with each other with respect to the function
modules used to handle the event.
Both will call a function module whose name they find in the workflow linkage
tables. swe_event_create will look in table SWETYPECOU while
swe_event_create_changedocument would look in SWECDOBJ for the name of the
function module.
If a name is found, the function module will then be called dynamically. This is all
to say about the linkage of the workflow.
The dynamic call looks like the following.
CALL FUNCTION swecdobj-objtypefb
EXPORTING
changedocument_header = changedocument_header
objecttype = swecdobj-objtype
IMPORTING
objecttype = swecdobj-objtype
TABLES
changedocument_position = changedocument_position.
Many SAP R/3 applications issue a call to the function SWE_EVENT_CREATE
during update. This function module ignites a simple workflow event.
Technically a workflow event is a timed call to a function module, which takes the
issuing event as the key to process a subsequent action.
If an application writes regular change documents (ger.: Änderungsbelege) to the
database, it will issue automatically a workflow event. This event is triggered from
within the function CHANGEDOCUMENT_CLOSE.
The change document workflow event is always triggered, independent of the case whether a change document is actually written.
In order to make use of the workflow for IDoc processing, you do not have to go
through the cumbersome workflow design procedure as it is described in the
workflow documentation. For the mentioned purpose, you can register the workflow
handler from the menu, which says Event Coupling from the BALD transaction.
Triggering the IDoc from a workflow event has a disadvantage: if the IDoc has to be
repeated for some reason, the event cannot be repeated easily. This is due to the
nature of a workflow event, which is triggered usually from a precedent action.
Therefore you have to find an own way how to make sure that the IDoc is actually
generated, even in the case of an error. Practically this is not a very big problem for IDocs. In most cases the creation of the IDoc will always take place. If there is a problem, then the IDoc would be stored in the IDoc base with a respective status. It will shown in transaction WE05 and can be resend from there.
Workflow Event From Change Document:
Most application fire a workflow event from the update routine by calling the
function
FUNCTION swe_event_create
You can check if an application fires events by activating the event log from
transaction SWLD. Calling and saving a transaction will write the event’s name and
circumstances into the log file.
If an application does not fire workflow events directly, there is still another chance that a workflow may be used without touching the R/3 original programs.
Every application that writes change documents triggers a workflow event from
within the function module CHANGEDOCUMENT_CLOSE, which is called form the
update processing upon writing the change document. This will call the workflow
processor.
FUNCTION swe_event_create_changedocument:
Both workflow types are not compatible with each other with respect to the function
modules used to handle the event.
Both will call a function module whose name they find in the workflow linkage
tables. swe_event_create will look in table SWETYPECOU while
swe_event_create_changedocument would look in SWECDOBJ for the name of the
function module.
If a name is found, the function module will then be called dynamically. This is all
to say about the linkage of the workflow.
The dynamic call looks like the following.
CALL FUNCTION swecdobj-objtypefb
EXPORTING
changedocument_header = changedocument_header
objecttype = swecdobj-objtype
IMPORTING
objecttype = swecdobj-objtype
TABLES
changedocument_position = changedocument_position.
Subscribe to:
Posts (Atom)













